
Relevant publications
Computational Imaging & Optics
Unsupervised physics-informed deep learning-based reconstruction for time-resolved imaging by multiplexed ptychography

We explore numerically an unsupervised, physics-informed, deep learning-based reconstruction technique for time-resolved imaging by multiplexed ptychography. In our method, the untrained deep learning model replaces the iterative algorithm’s update step, yielding superior reconstructions of multiple dynamic object frames compared to conventional methodologies. More precisely, we demonstrate improvements in image quality and resolution, while reducing sensitivity to the number of recorded frames, the mutual orthogonality of different probe modes, overlap between neighboring probe beams and the cutoff frequency of the ptychographic microscope – properties that are generally of paramount importance for ptychographic reconstruction algorithms.
Active propulsion noise shaping for multi-rotor aircraft localization
Multi-rotor aerial autonomous vehicles (MAVs) primarily rely on vision for navigation purposes. However, visual localization and odometry techniques suffer from poor performance in low or direct sunlight, a limited field of view, and vulnerability to occlusions. Acoustic sensing can serve as a complementary or even alternative modality for vision in many situations, and it also has the added benefits of lower system cost and energy footprint, which is especially important for micro aircraft. This paper proposes actively controlling and shaping the aircraft propulsion noise generated by the rotors to benefit localization tasks, rather than considering it a harmful nuisance. We present a neural network architecture for selfnoise-based localization in a known environment. We show that training it simultaneously with learning time-varying rotor phase modulation achieves accurate and robust localization. The proposed methods are evaluated using a computationally affordable simulation of MAV rotor noise in 2D acoustic environments that is fitted to real recordings of rotor pressure fields.
Designing nonlinear photonic crystals for high-dimensional quantum state engineering
We propose a novel, physically-constrained and differentiable approach for the generation of D-dimensional qudit states via spontaneous parametric downconversion (SPDC) in quantum optics. We circumvent any limitations imposed by the inherently stochastic nature of the physical process and incorporate a set of stochastic dynamical equations governing its evolution under the SPDC Hamiltonian. We demonstrate the effectiveness of our model through the design of
structured nonlinear photonic crystals (NLPCs) and shaped pump beams; and show, theoretically and experimentally, how to generate maximally entangled states in the spatial degree of freedom. The learning of NLPC structures offers a promising new avenue for shaping and controlling arbitrary quantum states and enables all-optical coherent control of the generated states. We believe that this approach can readily be extended from bulky crystals to thin Metasurfaces and potentially applied to other quantum systems sharing a similar Hamiltonian structures, such as superfluids and superconductors.
A machine learning approach to generate quantum light
Spontaneous parametric down-conversion (SPDC) is a key technique in quantum optics used to generate entangled photon pairs. However, generating a desirable D-dimensional qudit state in the SPDC process remains a challenge. In this paper, we introduce a physically-constrained and differentiable model to overcome this challenge, and demonstrate its effectiveness through the design of shaped pump beams and structured nonlinear photonic crystals. We avoid any restrictions induced by the stochastic nature of our physical process and integrate a set of stochastic dynamical equations governing its evolution under the SPDC Hamiltonian. Our model is capable of learning the relevant interaction parameters and designing nonlinear quantum optical systems that achieve desired quantum states. We show, theoretically and experimentally, how to generate maximally entangled states in the spatial degree of freedom. Additionally, we demonstrate all-optical coherent control of the generated state by reshaping the pump beam. Our work has potential applications in high-dimensional quantum key distribution and quantum information processing.
Towards predicting fine finger motions from ultrasound images via kinematic representation
A central challenge in building robotic prostheses is the creation of a sensor-based system able to read physiological signals from the lower limb and instruct a robotic hand to perform various tasks. Existing systems typically perform discrete gestures such as pointing or grasping, by employing electromyography (EMG) or ultrasound (US) technologies to analyze the state of the muscles. In this work, we study the inference problem of identifying the activation of specific fingers from a sequence of US images when performing dexterous tasks such as keyboard typing or playing the piano. While estimating finger gestures has been done in the past by detecting prominent gestures, we are interested in classification done in the context of fine motions that evolve over time. We consider this task as an important step towards higher adoption rates of robotic prostheses among arm amputees, as it has the potential to dramatically increase functionality in performing daily tasks. Our key observation, motivating this work, is that modeling the hand as a robotic manipulator allows to encode an intermediate representation wherein US images are mapped to said configurations. Given a sequence of such learned configurations, coupled with a neural-network architecture that exploits temporal coherence, we are able to infer fine finger motions. We evaluated our method by collecting data from a group of subjects and demonstrating how our framework can be used to replay music played or text typed. To the best of our knowledge, this is the first study demonstrating these downstream tasks within an end-to-end system.
Multi PILOT: Feasible learned multiple acquisition trajectories for dynamic MRI
Dynamic Magnetic Resonance Imaging (MRI) is known to be a powerful and reliable technique for the dynamic imaging of internal organs and tissues, making it a leading diagnostic tool. A major difficulty in using MRI in this setting is the relatively long acquisition time (and, hence, increased cost) required for imaging in high spatio-temporal resolution,
leading to the appearance of related motion artifacts and decrease in resolution. Compressed Sensing (CS) techniques have become a common tool to reduce MRI acquisition time by subsampling images in the k-space according to some acquisition trajectory. Several studies have particularly focused on applying deep learning techniques to learn these acquisition trajectories in order to attain better image reconstruction, rather than using some predefined set of trajectories. To the best of our knowledge, learning acquisition trajectories has been only explored in the context of static MRI. In this study, we consider acquisition trajectory learning in the dynamic imaging setting. We design an end-to-end pipeline for the joint optimization of multiple per-frame acquisition trajectories along with a reconstruction neural network, and demonstrate improved image reconstruction quality in shorter acquisition times.
Inverse design of spontaneous parametric downconversion for generation of high-dimensional qudits
Spontaneous parametric down-conversion in quantum optics is an invaluable resource for the realization of high-dimensional qudits with spatial modes of light. One of the main open challenges is how to directly generate a desirable qudit state in the SPDC process. This problem can be addressed through advanced computational learning methods; however, due to difficulties in modeling the SPDC process by a fully differentiable algorithm that takes into account all interaction effects, progress has been limited. Here, we overcome these limitations and introduce a physically-constrained and differentiable model, validated against experimental results for shaped pump beams and structured crystals, capable of learning every interaction parameter in the process. We avoid any restrictions induced by the stochastic nature of our physical model and integrate the dynamic equations governing the evolution under the SPDC Hamiltonian. We solve the inverse problem of designing a nonlinear quantum optical system that achieves the desired quantum state of down-converted photon pairs. The desired states are defined using either the second-order correlations between different spatial modes or by specifying the required density matrix. By learning nonlinear volume holograms as well as different pump shapes, we successfully show how to generate maximally entangled states. Furthermore, we simulate all-optical coherent control over the generated quantum state by actively changing the profile of the pump beam. Our work can be useful for applications such as novel designs of high-dimensional quantum key distribution and quantum information processing protocols. In addition, our method can be readily applied for controlling other degrees of freedom of light in the SPDC process, such as the spectral and temporal properties, and may even be used in condensed-matter systems having a similar interaction Hamiltonian.
Joint optimization of system design and reconstruction in MIMO radar imaging
Multiple-input multiple-output (MIMO) radar is one of the leading depth sensing modalities. However, the usage of multiple receive channels lead to relative high costs and prevent the penetration of MIMOs in many areas such as the automotive industry. Over the last years, few studies concentrated on designing reduced measurement schemes and image reconstruction schemes for MIMO radars, however these problems have been so far addressed separately. On the other hand, recent works in optical computational imaging have demonstrated growing success of simultaneous learningbased design of the acquisition and reconstruction schemes, manifesting significant improvement in the reconstruction quality. Inspired by these successes, in this work, we propose to learn MIMO acquisition parameters in the form of receive (Rx) antenna elements locations jointly with an image neuralnetwork based reconstruction. To this end, we propose an algorithm for training the combined acquisition-reconstruction pipeline end-to-end in a differentiable way. We demonstrate the significance of using our learned acquisition parameters with and without the neural-network reconstruction.
PILOT: Physics-Informed Learned Optimal Trajectories for accelerated MRI
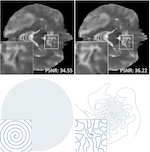
Magnetic Resonance Imaging (MRI) has long been considered to be among “the gold standards” of diagnostic medical imaging. The long acquisition times, however, render MRI prone to motion artifacts, let alone their adverse contribution to the relatively high costs of MRI examination. Over the last few decades, multiple studies have focused on the development of both physical and post-processing methods for accelerated acquisition of MRI scans. These two approaches, however, have so far been addressed separately. On the other hand, recent works in optical computational imaging have demonstrated growing success of the concurrent learning-based design of data acquisition and image reconstruction schemes. Such schemes have already demonstrated substantial effectiveness, leading to considerably shorter acquisition times and improved quality of image reconstruction. Inspired by this initial success, in this work, we propose a novel approach to the learning of optimal schemes for conjoint acquisition and reconstruction of MRI scans, with the optimization, carried out simultaneously with respect to the time-efficiency of data acquisition and the quality of resulting reconstructions. To be of practical value, the schemes are encoded in the form of general k-space trajectories, whose associated magnetic gradients are constrained to obey a set of predefined hardware requirements (as defined in terms of, e.g., peak currents and maximum slew rates of magnetic gradients). With this proviso in mind, we propose a novel algorithm for the end-to-end training of a combined acquisition-reconstruction pipeline using a deep neural network with differentiable forward- and backpropagation operators. We also demonstrate the effectiveness of the proposed solution in application to both image reconstruction and image segmentation, reporting substantial improvements in terms of acceleration factors as well as the quality of these end tasks.
Digital Gimbal: End-to-end deep image stabilization with learnable exposure times
Mechanical image stabilization using actuated gimbals enables capturing long-exposure shots without suffering from blur due to camera motion. These devices, however, are often physically cumbersome and expensive, limiting their widespread use. In this work, we propose to digitally emulate a mechanically stabilized system from the input of a fast unstabilized camera. To exploit the trade-off between motion blur at long exposures and low SNR at short exposures, we train a CNN that estimates a sharp high-SNR image by aggregating a burst of noisy short-exposure frames, related by unknown motion. We further suggest learning the burst’s exposure times in an end-to-end manner, thus balancing the noise and blur across the frames. We demonstrate this method’s advantage over the traditional approach of deblurring a single image or denoising a fixed-exposure burst.
Inverse design of quantum holograms in three-dimensional nonlinear photonic crystals
We introduce a systematic approach for designing 3D nonlinear photonic crystals and pump beams for generating desired quantum correlations between structured photon-pairs. Our model is fully differentiable, allowing accurate and efficient learning and discovery of novel designs.
3D FLAT: Feasible Learned Acquisition Trajectories for Accelerated MRI
Magnetic Resonance Imaging (MRI) has long been considered to be among the gold standards of today’s diagnostic imaging. The most significant drawback of MRI is long acquisition times, prohibiting its use in standard practice for some applications. Compressed sensing (CS) proposes to subsample the k-space (the Fourier domain dual to the physical space of spatial coordinates) leading to significantly accelerated acquisition. However, the benefit of compressed sensing has not been fully exploited; most of the sampling densities obtained through CS do not produce a trajectory that obeys the stringent constraints of the MRI machine imposed in practice. Inspired by recent success of deep learning-based approaches for image reconstruction and ideas from computational imaging on learning-based design of imaging systems, we introduce 3D FLAT, a novel protocol for data-driven design of 3D non-Cartesian accelerated trajectories in MRI. Our proposal leverages the entire 3D k-space to simultaneously learn a physically feasible acquisition trajectory with a reconstruction method. Experimental results, performed as a proof-of-concept, suggest that 3D FLAT achieves higher image quality for a given readout time compared to standard trajectories such as radial, stack-of-stars, or 2D learned trajectories (trajectories that evolve only in the 2D plane while fully sampling along the third dimension). Furthermore, we demonstrate evidence supporting the significant benefit of performing MRI acquisitions using non-Cartesian 3D trajectories over 2D non-Cartesian trajectories acquired slice-wise.
Towards learned optimal q-space sampling in diffusion MRI
Fiber tractography is an important tool of computational neuroscience that enables reconstructing the spatial connectivity and organization of white matter of the brain. Fiber tractography takes advantage of diffusion Magnetic Resonance Imaging (dMRI) which allows measuring the apparent diffusivity of cerebral water along different spatial directions. Unfortunately, collecting such data comes at the price of reduced spatial resolution and substantially elevated acquisition times, which limits the clinical applicability of dMRI. This problem has been thus far addressed using two principal strategies. Most of the efforts have been extended towards improving the quality of signal estimation for any, yet fixed sampling scheme (defined through the choice of diffusion encoding gradients). On the other hand, optimization over the sampling scheme has also proven to be effective. Inspired by the previous results, the present work consolidates the above strategies into a unified estimation framework, in which the optimization is carried out with respect to both estimation model and sampling design concurrently. The proposed solution offers substantial improvements in the quality of signal estimation as well as the accuracy of ensuing analysis by means of fiber tractography. While proving the optimality of the learned estimation models would probably need more extensive evaluation, we nevertheless claim that the learned sampling schemes can be of immediate use, offering a way to improve the dMRI analysis without the necessity of deploying the neural network used for their estimation. We present a comprehensive comparative analysis based on the Human Connectome Project data.
Joint learning of Cartesian undersampling and reconstruction for accelerated MRI
Magnetic Resonance Imaging (MRI) is considered today the golden-standard modality for soft tissues. The long acquisition times, however, make it more prone to motion artifacts as well as contribute to the relatively high costs of this examination. Over the years, multiple studies concentrated on designing reduced measurement schemes and image reconstruction schemes for MRI, however, these problems have been so far addressed separately. On the other hand, recent works in optical computational imaging have demonstrated growing success of the simultaneous learning-based design of the acquisition and reconstruction schemes manifesting significant improvement in the reconstruction quality with a constrained time budget. Inspired by these successes, in this work, we propose to learn accelerated MR acquisition schemes (in the form of Cartesian trajectories) jointly with the image reconstruction operator. To this end, we propose an algorithm for training the combined acquisition-reconstruction pipeline end-to-end in a differentiable way. We demonstrate the significance of using the learned Cartesian trajectories at different speed up rates.
Intel RealSense SR300 Coded light depth Camera

Intel RealSense SR300 is a depth camera capable of providing a VGA-size depth map at 60 fps and 0.125mm depth resolution. In addition, it outputs an infrared VGA-resolution image and a 1080p color texture image at 30 fps.
SR300 form-factor enables it to be integrated into small consumer products and as a front-facing camera in laptops and Ultrabooks. The SR300 depth camera is based on a coded-light technology where triangulation between projected patterns and images captured by a dedicated sensor is used to produce the depth map. Each projected line is coded by a special temporal optical code, that enables a dense depth map reconstruction from its reflection. The solid mechanical assembly of the camera allows it to stay calibrated throughout temperature and pressure changes, drops, and hits. In addition, active dynamic control maintains a calibrated depth output. An extended API LibRS released with the camera allows developers to integrate the camera in various applications. Algorithms for 3D scanning, facial analysis, hand gesture recognition, and tracking are within reach for applications using the SR300. In this paper, we describe the underlying technology, hardware, and algorithms of the SR300, as well as its calibration procedure, and outline some use cases. We believe that this paper will provide a full case study of a mass-produced depth sensing product and technology.
Self-supervised learning of inverse problem solvers in medical imaging
In the past few years, deep learning-based methods have demonstrated enormous success for solving inverse problems in medical imaging. In this work, we address the following question: Given a set of measurements obtained from real imaging experiments, what is the best way to use a learnable model and the physics of the modality to solve the inverse problem and reconstruct the latent image? Standard supervised learning based methods approach this problem by collecting data sets of known latent images and their corresponding measurements. However, these methods are often impractical due to the lack of availability of appropriately sized training sets, and, more generally, due to the inherent difficulty in measuring the “groundtruth” latent image. In light of this, we propose a self-supervised approach to training inverse models in medical imaging in the absence of aligned data. Our method only requiring access to the measurements and the forward model at training. We showcase its effectiveness on inverse problems arising in accelerated magnetic resonance imaging (MRI).
Depth estimation from a single image using deep learned phase coded mask

Depth estimation from a single image is a well-known challenge in computer vision. With the advent of deep learning, several approaches for monocular depth estimation have been proposed, all of which have inherent limitations due to the scarce depth cues that exist in a single image. Moreover, these methods are very demanding computationally, which makes them inadequate for systems with limited processing power. In this paper, a phase-coded aperture camera for depth estimation is proposed. The camera is equipped with an optical phase mask that provides unambiguous depth-related color characteristics for the captured image. These are used for estimating the scene depth map using a fully convolutional neural network. The phase-coded aperture structure is learned jointly with the network weights using backpropagation. The strong depth cues (encoded in the image by the phase mask, designed together with the network weights) allow a much simpler neural network architecture for faster and more accurate depth estimation. Performance achieved on simulated images as well as on a real optical setup is superior to the state-of-the-art monocular depth estimation methods (both with respect to the depth accuracy and required processing power), and is competitive with more complex and expensive depth estimation methods such as light-field cameras.
FPGA system for real-time computational extended depth of field imaging using phase aperture coding
We present a proof-of-concept end-to-end system for computational extended depth of field (EDOF) imaging. The acquisition is performed through a phase-coded aperture implemented by placing a thin wavelength-dependent op- tical mask inside the pupil of a conventional camera lens, as a result of which, each color channel is focused at a different depth. The reconstruction process re- ceives the raw Bayer image as the input, and performs blind estimation of the output color image in focus at an extended range of depths using a patch-wise sparse prior. We present a fast non-iterative reconstruction algorithm operating with constant latency in fixed-point arithmetics and achieving real-time perfor- mance in a prototype FPGA implementation. The output of the system, on simu- lated and real-life scenes, is qualitatively and quantitatively better than the result of clear-aperture imaging followed by state-of-the-art blind deblurring.
A Picture is Worth a Billion Bits: Real-time image reconstruction from dense binary pixels
The pursuit of smaller pixel sizes at ever-increasing resolution in digital image sensors is mainly driven by the stringent price and form-factor requirements of sensors and optics in the cellular phone market. Recently, Eric Fossum proposed a novel concept of an image sensor with dense sub-diffraction limit one-bit pixels (jots), which can be considered a digital emulation of silver halide photographic film. This idea has been recently embodied as the EPFL Gigavision camera. A major bottleneck in the design of such sensors is the image reconstruction process, producing a continuous high dynamic range image from oversampled bi- nary measurements. The extreme quantization of the Pois- son statistics is incompatible with the assumptions of most standard image processing and enhancement frameworks. The recently proposed maximum-likelihood (ML) approach addresses this difficulty, but suffers from image artifacts and has impractically high computational complexity. In this work, we study a variant of a sensor with binary thresh- old pixels and propose a reconstruction algorithm combin- ing an ML data fitting term with a sparse synthesis prior. We also show an efficient hardware-friendly real-time approximation of this inverse operator. Promising results are shown on synthetic data as well as on HDR data emulated using multiple exposures of a regular CMOS sensor.
Computational all-in-focus imaging using an optical phase mask

A method for extended depth of field imaging based on image acquisition through a thin binary phase plate followed by fast automatic computational post-processing is presented. By placing a wavelength dependent optical mask inside the pupil of a conventional camera lens, one acquires a unique response for each of the three main color channels, which adds valuable information that allows blind reconstruction of blurred images without the need of an iterative search process for estimating the blurring kernel. The presented simulation as well as capture of a real life scene show how acquiring a one-shot image focused at a single plane, enable generating a de-blurred scene over an extended range in space.
Real-time compressed imaging of scattering volumes

We propose a method and a prototype imaging system for real-time reconstruction of volumetric piecewise-smooth scattering media. The volume is illuminated by a sequence of structured binary patterns emitted from a fan beam projector, and the scattered light is collected by a two-dimensional sensor, thus creating an under-complete set of compressed measurements. We show a fixed-complexity and latency reconstruction algorithm capable of estimating the scattering coefficients in real-time. We also show a simple greedy algorithm for learning the optimal illumination patterns. Our results demonstrate faithful reconstruction from highly compressed measurements. Furthermore, a method for compressed registration of the measured volume to a known template is presented, showing excellent alignment with just a single projection. Though our prototype system operates in visible light, the presented methodology is suitable for fast x-ray scattering imaging, in particular in real-time vascular medical imaging.
3D color video camera

We introduce a design of a coded light-based 3D color video camera optimized for build up cost as well as accuracy in depth reconstruction and acquisition speed. The components of the system include a monochromatic camera and an off-the-shelf LED projector synchronized by a miniature circuit. The projected patterns are captured and processed at a rate of 200 fps and allow for real-time reconstruction of both depth and color at video rates. The reconstruction and display are performed at around 30 depth profiles and color texture per second using a graphics processing unit (GPU).
Embedded system for 3D shape reconstruction

Many applications that use three-dimensional scanning require a low cost, accurate and fast solution. This paper presents a fixed-point implementation of a real time active stereo threedimensional acquisition system on a Texas Instruments DM6446 EVM board which meets these requirements. A time-multiplexed structured light reconstruction technique is described and a fixed point algorithm for its implementation is proposed. This technique uses a standard camera and a standard projector. The fixed point reconstruction algorithm runs on the DSP core while the ARM controls the DSP and is responsible for communication with the camera and projector. The ARM uses the projector to project coded light and the camera to capture a series of images. The captured data is sent to the DSP. The DSP, in turn, performs the 3D reconstruction and returns the results to the ARM for storing. The inter-core communication is performed using the xDM interface and VISA API. Performance evaluation of a fully working prototype proves the feasibility of a fixed-point embedded implementation of a real time three-dimensional scanner, and the suitability of the DM6446 chip for such a system.