
Relevant publications
Dr. Or Litany
Contrast to divide: Self-supervised pre-training for learning with noisy labels
The success of learning with noisy labels (LNL) methods relies heavily on the success of a warm-up stage where standard supervised training is performed using the full (noisy) training set. In this paper, we identify a” warm-up obstacle”: the inability of standard warm-up stages to train high quality feature extractors and avert memorization of noisy labels. We propose” Contrast to Divide”(C2D), a simple framework that solves this problem by pre-training the feature extractor in a self-supervised fashion. Using self-supervised pre-training boosts the performance of existing LNL approaches by drastically reducing the warm-up stage’s susceptibility to noise level, shortening its duration, and improving extracted feature quality. C2D works out of the box with existing methods and demonstrates markedly improved performance, especially in the high noise regime, where we get a boost of more than 27% for CIFAR-100 with 90% noise over the previous state of the art. In real-life noise settings, C2D trained on mini-WebVision outperforms previous works both in WebVision and ImageNet validation sets by 3% top-1 accuracy. We perform an in-depth analysis of the framework, including investigating the performance of different pre-training approaches and estimating the effective upper bound of the LNL performance with semi-supervised learning.
Self-supervised learning of dense shape correspondence

We introduce the first completely unsupervised correspondence learning approach for deformable 3D shapes. Key to our model is the understanding that natural deformations (such as changes in the pose) approximately preserve the metric structure of the surface, yielding a natural criterion to drive the learning process toward distortion-minimizing predictions. On this basis, we overcome the need for annotated data and replace it with a purely geometric criterion. The resulting learning model is class-agnostic and is able to leverage any type of deformable geometric data for the training phase. In contrast to existing supervised approaches which specialize in the class seen at training time, we demonstrate stronger generalization as well as applicability to a variety of challenging settings. We showcase our method on a wide selection of correspondence benchmarks, where we outperform other methods in terms of accuracy, generalization, and efficiency.
Shape Correspondence with Isometric and Non-Isometric Deformations

The registration of surfaces with non-rigid deformation, especially non-isometric deformations, is a challenging problem. When applying such techniques to real scans, the problem is compounded by topological and geometric inconsistencies between shapes. In this paper, we capture a benchmark dataset of scanned 3D shapes undergoing various controlled deformations (articulating, bending, stretching and topologically changing), along with ground truth correspondences. With the aid of this tiered benchmark of increasingly challenging real scans, we explore this problem and investigate how robust current state-of-the-art methods perform in different challenging registration and correspondence scenarios. We discover that changes in topology is a challenging problem for some methods and that machine learning-based approaches prove to be more capable of handling non-isometric deformations on shapes that are moderately similar to the training set.
Partial single- and multi-shape dense correspondence using functional maps

Shape correspondence is a fundamental problem in computer graphics and vision, with applications in various problems including animation, texture mapping, robotic vision, medical imaging, archaeology and many more. In settings where the shapes are allowed to undergo non-rigid deformations and only partial views are available, the problem becomes very challenging. In this chapter we describe recent techniques designed to tackle such problems. Specifically, we explain how the renown functional maps framework can be extended to tackle the partial setting. We then present a further extension to the mutli-part case in which one tries to establish correspondence between a collection of shapes. Finally, we focus on improving the technique efficiency, by disposing of its spatial ingredient and thus keeping the computation in the spectral domain. Extensive experimental results are provided along with the theoretical explanations, to demonstrate the effectiveness of the described methods in these challenging scenarios.
Class-aware fully-convolutional Gaussian and Poisson denoising

We propose a fully-convolutional neural-network architecture for image denoising which is simple yet powerful. Its structure allows to exploit the gradual nature of the denoising process, in which shallow layers handle local noise statistics, while deeper layers recover edges and enhance textures. Our method advances the state-of-the-art when trained for different noise levels and distributions (both Gaussian and Poisson). In addition, we show that making the denoiser class-aware by exploiting semantic class information boosts performance, enhances textures and reduces artifacts.
Deep Functional Maps: Structured prediction for dense shape correspondence
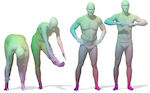
We introduce a new framework for learning dense correspondence between deformable 3D shapes. Existing learning based approaches model shape correspondence as a labelling problem, where each point of a query shape receives a label identifying a point on some reference domain; the correspondence is then constructed a posteriori by composing the label predictions of two input shapes. We propose a paradigm shift and design a structured prediction model in the space of functional maps, linear operators that provide a compact representation of the correspondence. We model the learning process via a deep residual network which takes dense descriptor fields defined on two shapes as input, and outputs a soft map between the two given objects. The resulting correspondence is shown to be accurate on several challenging benchmarks comprising multiple categories, synthetic models, real scans with acquisition artifacts, topological noise, and partiality.
Efficient deformable shape correspondence via kernel matching
We present a method to match three dimensional shapes under non-isometric deformations, topology changes and partiality. We formulate the problem as matching between a set of pair-wise and point-wise descriptors, imposing a continuity prior on the mapping, and propose a projected descent optimization procedure inspired by difference of convex functions (DC) programming. Surprisingly, in spite of the highly non-convex nature of the resulting quadratic assignment problem, our method converges to a semantically meaningful and continuous mapping in most of our experiments, and scales well. We provide preliminary theoretical analysis and several interpretations of the method.
White matter fiber representation using continuous dictionary learning

With increasingly sophisticated Diffusion Weighted MRI acquisition methods and modelling techniques, very large sets of streamlines (fibers) are presently generated per imaged brain. These reconstructions of white matter architecture, which are important for human brain research and pre-surgical planning, require a large amount of storage and are often unwieldy and difficult to manipulate and analyze. This work proposes a novel continuous parsimonious framework in which signals are sparsely represented in a dictionary with continuous atoms. The significant innovation in our new methodology is the ability to train such continuous dictionaries, unlike previous approaches that either used pre-fixed continuous transforms or training with finite atoms. This leads to an innovative fiber representation method, which uses Continuous Dictionary Learning to sparsely code each fiber with high accuracy. This method is tested on numerous tractograms produced from the Human Connectome Project data and achieves state-of-the-art performances in compression ratio and reconstruction error.
Fully spectral partial shape matching

We propose an efficient procedure for calculating partial dense intrinsic correspondence between deformable shapes performed entirely in the spectral domain. Our technique relies on the recently introduced partial functional maps formalism and on the joint approximate diagonalization (JAD) of the Laplace-Beltrami operators previously introduced for matching non-isometric shapes. We show that a variant of the JAD problem with an appropriately modified coupling term (surprisingly) allows to construct quasi-harmonic bases localized on the latent corresponding parts. This circumvents the need to explicitly compute the unknown parts by means of the cumbersome alternating minimization used in the previous approaches, and allows performing all the calculations in the spectral domain with constant complexity independent of the number of shape vertices. We provide an extensive evaluation of the proposed technique on standard non-rigid correspondence benchmarks and show state-of-the-art performance in various settings, including partiality and the presence of topological noise.
Deep class-aware image denoising

The increasing demand for high image quality in mobile devices brings forth the need for better computational enhancement techniques, and image denoising in particular. To this end, we propose a new fully convolutional deep neural network architecture which is simple yet powerful and achieves state-of-the-art performance for additive Gaussian noise removal. Furthermore, we claim that the personal photo-collections can usually be categorized into a small set of semantic classes. However simple, this observation has not been exploited in image denoising until now. We show that a significant boost in performance of up to 0.4dB PSNR can be achieved by making our network class-aware, namely, by fine-tuning it for images belonging to a specific semantic class. Relying on the hugely successful existing image classifiers, this research advocates for using a class-aware approach in all image enhancement tasks.
Cloud Dictionary: Sparse coding and modeling for point clouds
With the development of range sensors such as LIDAR and time-of-flight cameras, 3D point cloud scans have become ubiquitous in computer vision applications, the most prominent ones being gesture recognition and autonomous driving. Parsimony-based algorithms have shown great success on images and videos where data points are sampled on a regular Cartesian grid. We propose an adaptation of these techniques to irregularly sampled signals by using continuous dictionaries. We present an example application in the form of point cloud denoising.
Deep class-aware denoising
The increasing demand for high image quality in mobile devices brings forth the need for better computational enhancement techniques, and image denoising in particular. At the same time, the images captured by these devices can be categorized into a small set of semantic classes. However simple, this observation has not been exploited in image denoising until now. In this paper, we demonstrate how the reconstruction quality improves when a denoiser is aware of the type of content in the image. To this end, we first propose a new fully convolutional deep neural network architecture which is simple yet powerful as it achieves state-of-the-art performance even without be- ing class-aware. We further show that a significant boost in performance of up to 0.4 dB PSNR can be achieved by making our network class-aware, namely, by fine-tuning it for images belonging to a specific semantic class. Relying on the hugely successful existing image classifiers, this research advocates for using a class-aware approach in all image enhancement tasks.
Deep convolutional denoising of low-light images
Poisson distribution is used for modeling noise in photon-limited imaging. While canonical examples include relatively exotic types of sensing like spectral imaging or astronomy, the problem is relevant to regular photography now more than ever due to the booming market for mobile cameras. Restricted form factor limits the amount of absorbed light, thus computational post-processing is called for. In this paper, we make use of the powerful framework of deep convolutional neural networks for Poisson denoising. We demonstrate how by training the same network with images having a specific peak value, our denoiser outperforms previous state-of-the-art by a large margin both visually and quantitatively. Being flexible and data-driven, our solution resolves the heavy ad hoc engineering used in previous methods and is an order of magnitude faster. We further show that by adding a reasonable prior on the class of the image being processed, another significant boost in performance is achieved.
ASIST: Automatic Semantically Invariant Scene Transformation

We present ASIST, a technique for transforming point clouds by replacing objects with their semantically equivalent counterparts. Transformations of this kind have applications in virtual reality, repair of fused scans, and robotics. ASIST is based on a unified formulation of semantic labeling and object replacement; both result from minimizing a single objective. We present numerical tools for the efficient solution of this optimization problem. The method is experimentally assessed on new datasets of both synthetic and real point clouds, and is additionally compared to two recent works on object replacement on data from the corresponding papers.
FPGA system for real-time computational extended depth of field imaging using phase aperture coding
We present a proof-of-concept end-to-end system for computational extended depth of field (EDOF) imaging. The acquisition is performed through a phase-coded aperture implemented by placing a thin wavelength-dependent op- tical mask inside the pupil of a conventional camera lens, as a result of which, each color channel is focused at a different depth. The reconstruction process re- ceives the raw Bayer image as the input, and performs blind estimation of the output color image in focus at an extended range of depths using a patch-wise sparse prior. We present a fast non-iterative reconstruction algorithm operating with constant latency in fixed-point arithmetics and achieving real-time perfor- mance in a prototype FPGA implementation. The output of the system, on simu- lated and real-life scenes, is qualitatively and quantitatively better than the result of clear-aperture imaging followed by state-of-the-art blind deblurring.
Non-rigid puzzles

Shape correspondence is a fundamental problem in computer graphics and vision, with applications in various problems including animation, texture mapping, robotic vision, medical imaging, archaeology and many more. In settings where the shapes are allowed to undergo non-rigid deformations and only partial views are available, the problem becomes very challenging. To this end, we present a non-rigid multi-part shape matching algorithm. We assume to be given a reference shape and its multiple parts undergoing a non-rigid deformation. Each of these query parts can be additionally contaminated by clutter, may overlap with other parts, and there might be missing parts or redundant ones. Our method simultaneously solves for the segmentation of the reference model, and for a dense correspondence to (subsets of) the parts. Experimental results on synthetic as well as real scans demonstrate the effectiveness of our method in dealing with this challenging matching scenario.
A Picture is Worth a Billion Bits: Real-time image reconstruction from dense binary pixels
The pursuit of smaller pixel sizes at ever-increasing resolution in digital image sensors is mainly driven by the stringent price and form-factor requirements of sensors and optics in the cellular phone market. Recently, Eric Fossum proposed a novel concept of an image sensor with dense sub-diffraction limit one-bit pixels (jots), which can be considered a digital emulation of silver halide photographic film. This idea has been recently embodied as the EPFL Gigavision camera. A major bottleneck in the design of such sensors is the image reconstruction process, producing a continuous high dynamic range image from oversampled bi- nary measurements. The extreme quantization of the Pois- son statistics is incompatible with the assumptions of most standard image processing and enhancement frameworks. The recently proposed maximum-likelihood (ML) approach addresses this difficulty, but suffers from image artifacts and has impractically high computational complexity. In this work, we study a variant of a sensor with binary thresh- old pixels and propose a reconstruction algorithm combin- ing an ML data fitting term with a sparse synthesis prior. We also show an efficient hardware-friendly real-time approximation of this inverse operator. Promising results are shown on synthetic data as well as on HDR data emulated using multiple exposures of a regular CMOS sensor.
Putting the pieces together: regularized multi-shape partial matching

Multi-part shape matching in an important class of problems, arising in many fields such as computational archaeology, biology, geometry processing, computer graphics and vision. In this paper, we address the problem of simultaneous matching and segmentation of multiple shapes. We assume to be given a reference shape and multiple parts partially matching the reference. Each of these parts can have additional clutter, have overlap with other parts, or there might be missing parts. We show experimental results of efficient and accurate assembly of fractured synthetic and real objects.