
Relevant publications
Computer Vision
Sample- and parameter-efficient auto-regressive image models

We introduce XTRA, a vision model pre-trained with a novel auto-regressive objective that significantly enhances both sample and parameter efficiency compared to previous auto-regressive image models. Unlike contrastive or masked image modeling methods, which have not been demonstrated as having consistent scaling behavior on unbalanced internet data, auto-regressive vision models exhibit scalable and promising performance as model and dataset size increase. In contrast to standard auto-regressive models, XTRA employs a Block Causal Mask, where each Block represents k × k tokens rather than relying on a standard causal mask. By reconstructing pixel values block by block, XTRA captures higher-level structural patterns over larger image regions. Predicting on blocks allows the model to learn relationships across broader areas of pixels, enabling more abstract and semantically meaningful representations than traditional next-token prediction. This simple modification yields two key results. First, XTRA is sample-efficient. Despite being trained on 152× fewer samples (13.1M vs. 2B), XTRA ViT-H/14 surpasses the top-1 average accuracy of the previous state-of-the-art auto-regressive model across 15 diverse image recognition benchmarks. Second, XTRA is parameter-efficient. Compared to auto-regressive models trained on ImageNet-1k, XTRA ViT-B/16 outperforms in linear and attentive probing tasks, using 7-16× fewer parameters (85M vs. 1.36B/0.63B).
Towards predicting fine finger motions from ultrasound images via kinematic representation
A central challenge in building robotic prostheses is the creation of a sensor-based system able to read physiological signals from the lower limb and instruct a robotic hand to perform various tasks. Existing systems typically perform discrete gestures such as pointing or grasping, by employing electromyography (EMG) or ultrasound (US) technologies to analyze the state of the muscles. In this work, we study the inference problem of identifying the activation of specific fingers from a sequence of US images when performing dexterous tasks such as keyboard typing or playing the piano. While estimating finger gestures has been done in the past by detecting prominent gestures, we are interested in classification done in the context of fine motions that evolve over time. We consider this task as an important step towards higher adoption rates of robotic prostheses among arm amputees, as it has the potential to dramatically increase functionality in performing daily tasks. Our key observation, motivating this work, is that modeling the hand as a robotic manipulator allows to encode an intermediate representation wherein US images are mapped to said configurations. Given a sequence of such learned configurations, coupled with a neural-network architecture that exploits temporal coherence, we are able to infer fine finger motions. We evaluated our method by collecting data from a group of subjects and demonstrating how our framework can be used to replay music played or text typed. To the best of our knowledge, this is the first study demonstrating these downstream tasks within an end-to-end system.
Intra-class low-rank regularization for supervised and semi-supervised cross-modal retrieval
Cross-modal retrieval aims to retrieve related items across different modalities, for example, using an image query to retrieve related text. The existing deep methods ignore both the intra-modal and inter-modal intra-class low-rank structures when fusing various modalities, which decreases the retrieval performance. In this paper, two deep models (denoted as ILCMR and Semi-ILCMR) based on intra-class low-rank regularization are proposed for supervised and semi-supervised cross-modal retrieval, respectively. Specifically, ILCMR integrates the image network and text network into a unified framework to learn a common feature space by imposing three regularization terms to fuse the cross-modal data. First, to align them in the label space, we utilize semantic consistency regularization to convert the data representations to probability distributions over the classes. Second, we introduce an intra-modal low-rank regularization, which encourages the intra-class samples that originate from the same space to be more relevant in the common feature space. Third, an inter-modal low-rank regularization is applied to reduce the cross-modal discrepancy. To enable the low-rank regularization to be optimized using automatic gradients during network back-propagation, we propose the rank-r approximation and specify the explicit gradients for theoretical completeness. In addition to the three regularization terms that rely on label information incorporated by ILCMR, we propose Semi-ILCMR in the semi-supervised regime, which introduces a low-rank constraint before projecting the general representations into the common feature space. Extensive experiments on four public cross-modal datasets demonstrate the superiority of ILCMR and Semi-ILCMR over other state-of-the-art methods.
Physical passive patch adversarial attacks on visual odometry systems
Deep neural networks are known to be susceptible to adversarial perturbations — small perturbations that alter the output of the network and exist under strict norm limitations. While such perturbations are usually discussed as tailored to a specific input, a universal perturbation can be constructed to alter the model’s output on a set of inputs. Universal perturbations present a more realistic case of adversarial attacks, as awareness of the model’s exact input is not required. In addition, the universal attack setting raises the subject of generalization to unseen data, where given a set of inputs, the universal perturbations aim to alter the model’s output on out-of-sample data. In this work, we study physical passive patch adversarial attacks on visual odometry-based autonomous navigation systems. A visual odometry system aims to infer the relative camera motion between two corresponding viewpoints, and is frequently used by vision-based autonomous navigation systems to estimate their state. For such navigation systems, a patch adversarial perturbation poses a severe security issue, as it can be used to mislead a system onto some collision course. To the best of our knowledge, we show for the first time that the error margin of a visual odometry model can be significantly increased by deploying patch adversarial attacks in the scene. We provide evaluation on synthetic closed-loop drone navigation data and demonstrate that a comparable vulnerability exists in real data.
Contrast to divide: Self-supervised pre-training for learning with noisy labels
The success of learning with noisy labels (LNL) methods relies heavily on the success of a warm-up stage where standard supervised training is performed using the full (noisy) training set. In this paper, we identify a” warm-up obstacle”: the inability of standard warm-up stages to train high quality feature extractors and avert memorization of noisy labels. We propose” Contrast to Divide”(C2D), a simple framework that solves this problem by pre-training the feature extractor in a self-supervised fashion. Using self-supervised pre-training boosts the performance of existing LNL approaches by drastically reducing the warm-up stage’s susceptibility to noise level, shortening its duration, and improving extracted feature quality. C2D works out of the box with existing methods and demonstrates markedly improved performance, especially in the high noise regime, where we get a boost of more than 27% for CIFAR-100 with 90% noise over the previous state of the art. In real-life noise settings, C2D trained on mini-WebVision outperforms previous works both in WebVision and ImageNet validation sets by 3% top-1 accuracy. We perform an in-depth analysis of the framework, including investigating the performance of different pre-training approaches and estimating the effective upper bound of the LNL performance with semi-supervised learning.
Delta-GAN-Encoder: Encoding semantic changes for explicit image editing, using few synthetic samples
Understating and controlling generative models’ latent space is a complex task. In this paper, we propose a novel method for learning to control any desired attribute in a pre-trained GAN’s latent space, for the purpose of editing synthesized and real-world data samples accordingly. We perform Sim2Real learning, relying on minimal samples to achieve an unlimited amount of continuous precise edits. We present an Autoencoder-based model that learns to encode the semantics of changes between images as a basis for editing new samples later on, achieving precise desired results – example shown in Fig. 1. While previous editing methods rely on a known structure of latent spaces (e.g., linearity of some semantics in StyleGAN), our method inherently does not require any structural constraints. We demonstrate our method in the domain of facial imagery: editing different expressions, poses, and lighting attributes, achieving state-of-the-art results.
Detector-free weakly supervised grounding by separation
Nowadays, there is an abundance of data involving images and surrounding free-form text weakly corresponding to those images. Weakly Supervised phrase-Grounding (WSG) deals with the task of using this data to learn to localize (or to ground) arbitrary text phrases in images without any additional annotations. However, most recent SotA methods for WSG assume the existence of a pre-trained object detector, relying on it to produce the ROIs for localization. In this work, we focus on the task of Detector-Free WSG (DF-WSG) to solve WSG without relying on a pre-trained detector. We directly learn everything from the images and associated free-form text pairs, thus potentially gaining an advantage on the categories unsupported by the detector. The key idea behind our proposed Grounding by Separation (GbS) method is synthesizing `text to image-regions’ associations by random alpha-blending of arbitrary image pairs and using the corresponding texts of the pair as conditions to recover the alpha map from the blended image via a segmentation network. At test time, this allows using the query phrase as a condition for a non-blended query image, thus interpreting the test image as a composition of a region corresponding to the phrase and the complement region. Using this approach we demonstrate a significant accuracy improvement, of up to 8.5% over previous DF-WSG SotA, for a range of benchmarks including Flickr30K, Visual Genome, and ReferIt, as well as a significant complementary improvement (above 7%) over the detector-based approaches for WSG.
MetAdapt: Meta-learned task-adaptive architecture for few-shot classification
Few-Shot Learning (FSL) is a topic of rapidly growing interest. Typically, in FSL a model is trained on a dataset consisting of many small tasks (meta-tasks) and learns to adapt to novel tasks that it will encounter during test time. This is also referred to as meta-learning. Another topic closely related to meta-learning with a lot of interest in the community is Neural Architecture Search (NAS), automatically finding optimal architecture instead of engineering it manually. In this work we combine these two aspects of meta-learning. So far, meta-learning FSL methods have focused on optimizing parameters of pre-defined network architectures, in order to make them easily adaptable to novel tasks. Moreover, it was observed that, in general, larger architectures perform better than smaller ones up to a certain saturation point (where they start to degrade due to over-fitting). However, little attention has been given to explicitly optimizing the architectures for FSL, nor to an adaptation of the architecture at test time to particular novel tasks. In this work, we propose to employ tools inspired by the Differentiable Neural Architecture Search (D-NAS) literature in order to optimize the architecture for FSL without over-fitting. Additionally, to make the architecture task adaptive, we propose the concept of ‘MetAdapt Controller’ modules. These modules are added to the model and are meta-trained to predict the optimal network connections for a given novel task. Using the proposed approach we observe state-of-the-art resu
Self-supervised classification network
We present Self-Classifier — a novel self-supervised end-to-end classification neural network. Self-Classifier learns labels and representations simultaneously in a single-stage end-to-end manner by optimizing for same-class prediction of two augmented views of the same sample. To guarantee non-degenerate solutions (i.e., solutions where all labels are assigned to the same class), a uniform prior is asserted on the labels. We show mathematically that unlike the regular cross-entropy loss, our approach avoids such solutions. Self-Classifier is simple to implement and is scalable to practically unlimited amounts of data. Unlike other unsupervised classification approaches, it does not require any form of pre-training or the use of expectation maximization algorithms, pseudo-labelling or external clustering. Unlike other contrastive learning representation learning approaches, it does not require a memory bank or a second network. Despite its relative simplicity, our approach achieves comparable results to state-of-the-art performance with ImageNet, CIFAR10 and CIFAR100 for its two objectives: unsupervised classification and unsupervised representation learning. Furthermore, it is the first unsupervised end-to-end classification network to perform well on the large-scale ImageNet dataset. Code will be made available.
Learning to localize objects using limited annotation with applications to thoracic diseases
Motivation: The localization of objects in images is a longstanding objective within the field of image processing. Most current techniques are based on machine learning approaches, which typically require careful annotation of training samples in the form of expensive bounding box labels. The need for such large-scale annotation has only been exacerbated by the widespread adoption of deep learning techniques within the image processing community: deep learning is notoriously data-hungry. Method: In this work, we attack this problem directly by providing a new method for learning to localize objects with limited annotation: most training images can simply be annotated with their whole image labels (and no bounding box), with only a small fraction marked with bounding boxes. The training is driven by a novel loss function, which is a continuous relaxation of a well-defined discrete formulation of weakly supervised learning. Care is taken to ensure that the loss is numerically well-posed. Additionally, we propose a neural network architecture which accounts for both patch dependence, through the use of Conditional Random Field layers, and shift-invariance, through the inclusion of anti-aliasing filters. Results: We demonstrate our method on the task of localizing thoracic diseases in chest X-ray images, achieving state-of-the-art performance on the ChestX-ray14 dataset. We further show that with a modicum of additional effort our technique can be extended from object localization to object detection, attaining high quality results on the Kaggle RSNA Pneumonia Detection Challenge. Conclusion: The technique presented in this paper has the potential to enable high accuracy localization in regimes in which annotated data is either scarce or expensive to acquire. Future work will focus on applying the ideas presented in this paper to the realm of semantic segmentation.
StarNet: towards weakly supervised few-shot detection and explainable few-shot classification
In this paper, we propose a new few-shot learning method called StarNet, which is an end-to-end trainable non-parametric star-model few-shot classifier. While being meta-trained using only image-level class labels, StarNet learns not only to predict the class labels for each query image of a few-shot task, but also to localize (via a heatmap) what it believes to be the key image regions supporting its prediction, thus effectively detecting the instances of the novel categories. The localization is enabled by the StarNet’s ability to find large, arbitrarily shaped, semantically matching regions between all pairs of support and query images of a few-shot task. We evaluate StarNet on multiple few-shot classification benchmarks attaining significant state-of-the-art improvement on the CUB and ImageNetLOC-FS, and smaller improvements on other benchmarks. At the same time, in many cases, StarNet provides plausible explanations for its class label predictions, by highlighting the correctly paired novel category instances on the query and on its best matching support (for the predicted class). In addition, we test the proposed approach on the previously unexplored and challenging task of Weakly Supervised Few-Shot Object Detection (WS-FSOD), obtaining significant improvements over the baselines.
Noise estimation using density estimation for self-supervised multimodal learning
One of the key factors of enabling machine learning models to comprehend and solve real-world tasks is to leverage multimodal data. Unfortunately, the annotation of multimodal data is challenging and expensive. Recently, self-supervised multimodal methods that combine vision and language were proposed to learn multimodal representations without annotation. However, these methods choose to ignore the presence of high levels of noise and thus yield sub-optimal results. In this work, we show that the problem of noise estimation for multimodal data can be reduced to a multimodal density estimation task. Using multimodal density estimation, we propose a noise estimation building block for multimodal representation learning that is based strictly on the inherent correlation between different modalities. We demonstrate how our noise estimation can be broadly integrated and achieves comparable results to state-of-the-art performance on five different benchmark datasets for two challenging multimodal tasks: Video Question Answering and Text-To-Video Retrieval.
Digital Gimbal: End-to-end deep image stabilization with learnable exposure times
Mechanical image stabilization using actuated gimbals enables capturing long-exposure shots without suffering from blur due to camera motion. These devices, however, are often physically cumbersome and expensive, limiting their widespread use. In this work, we propose to digitally emulate a mechanically stabilized system from the input of a fast unstabilized camera. To exploit the trade-off between motion blur at long exposures and low SNR at short exposures, we train a CNN that estimates a sharp high-SNR image by aggregating a burst of noisy short-exposure frames, related by unknown motion. We further suggest learning the burst’s exposure times in an end-to-end manner, thus balancing the noise and blur across the frames. We demonstrate this method’s advantage over the traditional approach of deblurring a single image or denoising a fixed-exposure burst.
Self-supervised learning for large-scale unsupervised image clustering
Unsupervised learning has always been appealing to machine learning researchers and practitioners, allowing them to avoid an expensive and complicated process of labeling the data. However, unsupervised learning of complex data is challenging, and even the best approaches show much weaker performance than their supervised counterparts. Self-supervised deep learning has become a strong instrument for representation learning in computer vision. However, those methods have not been evaluated in a fully unsupervised setting.
In this paper, we propose a simple scheme for unsupervised classification based on self-supervised representations. We evaluate the proposed approach with several recent self-supervised methods showing that it achieves competitive results for ImageNet classification (39% accuracy on ImageNet with 1000 clusters and 46% with overclustering). We suggest adding the unsupervised evaluation to a set of standard benchmarks for self-supervised learning.
Do we need depth in state-of-the-art face authentication?
Some face recognition methods are designed to utilize geometric features extracted from depth sensors to handle the challenges of single-image based recognition technologies. However, calculating the geometrical data is an expensive and challenging process. Here, we introduce a novel method that learns distinctive geometric features from stereo camera systems without the need to explicitly compute the facial surface or depth map. The raw face stereo images along with coordinate maps allow a CNN to learn geometric features. This way, we keep the simplicity and cost-efficiency of recognition from a single image, while enjoying the benefits of geometric data without explicitly reconstructing it. We demonstrate that the suggested method outperforms both existing single-image and explicit depth-based methods on large-scale benchmarks. We also provide an ablation study to show that the suggested method uses the coordinate maps to encode more informative features.
Smoothed inference for adversarially-trained models
Deep neural networks are known to be vulnerable to inputs with maliciously constructed adversarial perturbations aimed at forcing misclassification. We study randomized smoothing as a way to both improve performance on unperturbed data as well as increase robustness to adversarial attacks. Moreover, we extend the method proposed by arXiv:1811.09310 by adding low-rank multivariate noise, which we then use as a base model for smoothing. The proposed method achieves 58.5% top-1 accuracy on CIFAR-10 under PGD attack and outperforms previous works by 4%. In addition, we consider a family of attacks, which were previously used for training purposes in the certified robustness scheme. We demonstrate that the proposed attacks are more effective than PGD against both smoothed and non-smoothed models. Since our method is based on sampling, it lends itself well for trading-off between the model inference complexity and its performance. A reference implementation of the proposed techniques is provided.
MetAdapt: Meta-learned task-adaptive architecture for few-shot classification
Few-Shot Learning (FSL) is a topic of rapidly growing interest. Typically, in FSL a model is trained on a dataset consisting of many small tasks (meta-tasks) and learns to adapt to novel tasks that it will encounter during test time. This is also referred to as meta-learning. So far, meta-learning FSL methods have focused on optimizing parameters of pre-defined network architectures, in order to make them easily adaptable to novel tasks. Moreover, it was observed that, in general, larger architectures perform better than smaller ones up to a certain saturation point (and even degrade due to over-fitting). However, little attention has been given to explicitly optimizing the architectures for FSL, nor to an adaptation of the architecture at test time to particular novel tasks. In this work, we propose to employ tools borrowed from the Differentiable Neural Architecture Search (D-NAS) literature in order to optimize the architecture for FSL without over-fitting. Additionally, to make the architecture task adaptive, we propose the concept of `MetAdapt Controller’ modules. These modules are added to the model and are meta-trained to predict the optimal network connections for a given novel task. Using the proposed approach we observe state-of-the-art results on two popular few-shot benchmarks: miniImageNet and FC100.
RepMet: Representative-based metric learning for classification and one-shot object detection
Distance metric learning (DML) has been successfully applied to object classification, both in the standard regime of rich training data and in the few-shot scenario, where each category is represented by only few examples. In this work, we propose a new method for DML, featuring a joint learning of the embedding space and of the data distribution of the training categories, in a single training process. Our method improves upon leading algorithms for DML-based object classification. Furthermore, it opens the door for a new task in computer vision — a few-shot object detection, since the proposed DML architecture can be naturally embedded as the classification head of any standard object detector. In numerous experiments, we achieve state-of-the-art classification results on a variety of fine-grained datasets, and offer the community a benchmark on the few-shot detection task, performed on the Imagenet-LOC dataset.
ForestHash: Semantic hashing with shallow random forests and tiny convolutional networks
Hash codes are efficient data representations for coping with the ever growing amounts of data. In this paper, we introduce a random forest semantic hashing scheme that embeds tiny convolutional neural networks (CNN) into shallow random forests, with near-optimal information-theoretic code aggregation among trees. We start with a simple hashing scheme, where random trees in a forest act as hashing functions by setting `1′ for the visited tree leaf, and `0′ for the rest. We show that traditional random forests fail to generate hashes that preserve the underlying similarity between the trees, rendering the random forests approach to hashing challenging. To address this, we propose to first randomly group arriving classes at each tee split node into two groups, obtaining a significantly simplified two-class classification problem, which can be handled using a light-weight CNN weak learner. Such random class grouping scheme enables code uniqueness by enforcing each class to share its code with different classes in different trees. A non-conventional low-rank loss is further adopted for the CNN weak learners to encourage code consistency by minimizing intra-class variations and maximizing inter-class distance for the two random class groups. Finally, we introduce an information-theoretic approach for aggregating codes of individual trees into a single hash code, producing a near-optimal unique hash for each class. The proposed approach significantly outperforms state-of-the-art hashing methods for image retrieval tasks on large-scale public datasets, while performing at the level of other state-of-the-art image classification techniques while utilizing a more compact and efficient scalable representation. This work proposes a principled and robust procedure to train and deploy in parallel an ensemble of light-weight CNNs, instead of simply going deeper.
Sparsity and nullity: paradigms for analysis dictionary learning

Sparse models in dictionary learning have been successfully applied in a wide variety of machine learning and computer vision problems, and as a result, have recently attracted increased research interest. Another interesting related problem based on linear equality constraints, namely the sparse null space (SNS) problem, first appeared in 1986 and has since inspired results on sparse basis pursuit. In this paper, we investigate the relation between the SNS problem and the analysis dictionary learning (ADL) problem, and show that the SNS problem plays a central role, and may be utilized to solve dictionary learning problems. Moreover, we propose an efficient algorithm of sparse null space basis pursuit (SNS-BP) and extend it to a solution of ADL. Experimental results on numerical synthetic data and real-world data are further presented to validate the performance of our method.
GMD: Global model detection via inlier rate estimation
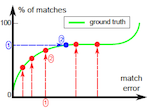
This work presents a novel approach for detecting inliers in a given set of correspondences (matches). It does so without explicitly identifying any consensus set, based on a method for inlier rate estimation (IRE). Given such an estimator for the inlier rate, we also present an algorithm that detects a globally optimal transformation. We provide a theoretical analysis of the IRE method using a stochastic generative model on the continuous spaces of matches and transformations. This model allows rigorous investigation of the limits of our IRE method for the case of 2D translation, further giving bounds and insights for the more general case. Our theoretical analysis is validated empirically and is shown to hold in practice for the more general case of 2D affinities. In addition, we show that the combined framework works on challenging cases of 2D homography estimation, with very few and possibly noisy inliers, where RANSAC generally fails.
Probably approximately symmetric: Fast rigid symmetry detection with global guarantees
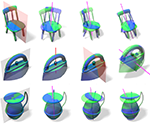
We present a fast algorithm for global 3D symmetry detection with approximation guarantees. The algorithm is guaranteed to find the best approximate symmetry of a given shape, to within a user-specified threshold, with very high probability. Our method uses a carefully designed sampling of the transformation space, where each transformation is efficiently evaluated using a sub-linear algorithm. We prove that the density of the sampling depends on the total variation of the shape, allowing us to derive formal bounds on the algorithm’s complexity and approximation quality. We further investigate different volumetric shape representations (in the form of truncated distance transforms), and in such a way control the total variation of the shape and hence the sampling density and the runtime of the algorithm. A comprehensive set of experiments assesses the proposed method, including an evaluation on the eight categories of the COSEG data-set. This is the first large-scale evaluation of any symmetry detection technique that we are aware of.
Intrinsic shape context descriptors for deformable shapes
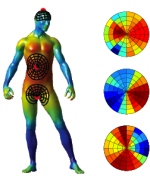
In this work, we present intrinsic shape context (ISC) descriptors for 3D shapes. We generalize to surfaces the polar sampling of the image domain used in shape contexts; for this purpose, we chart the surface by shooting geodesic outwards from the point being analyzed; ‘angle’ is treated as tantamount to geodesic shooting direction, and radius as geodesic distance. To deal with orientation ambiguity, we exploit properties of the Fourier transform. Our charting method is intrinsic, i.e., invariant to isometric shape transformations. The resulting descriptor is a meta-descriptor that can be applied to any photometric or geometric property field defined on the shape, in particular, we can leverage recent developments in intrinsic shape analysis and construct ISC based on state-of-the-art dense shape descriptors such as heat kernel signatures. Our experiments demonstrate a notable improvement in shape matching on standard benchmarks.
Articulated motion segmentation of point clouds by group-valued regularization

Motion segmentation for articulated objects is an important topic of research. Yet such a segmentation should be as free as possible from underlying assumptions so as to fit general scenes and objects. In this paper we demonstrate an algorithm for articulated motion segmentation of 3D point clouds, free of any assumptions on the underlying model and yet firmly set in a well-defined variational framework. Results on scanned images show the generality of the proposed technique and its robustness to scanning artifacts and noise.
LDAHash: improved matching with smaller descriptors

SIFT-like local feature descriptors are ubiquitously employed in such computer vision applications as content-based retrieval, video analysis, copy detection, object recognition, photo-tourism, and 3D reconstruction from multiple views. Feature descriptors can be designed to be invariant to certain classes of photometric and geometric transformations, in particular, affine and intensity scale transformations. However, real transformations that an image can undergo can only be approximately modeled in this way, and thus most descriptors are only approximately invariant in practice. Secondly, descriptors are usually high-dimensional (e.g. SIFT is represented as a 128-dimensional vector). In large-scale retrieval and matching problems, this can pose challenges in storing and retrieving descriptor data. We propose mapping the descriptor vectors into the Hamming space, in which the Hamming metric is used to compare the resulting representations. This way, we reduce the size of the descriptors by representing them as short binary strings and learn descriptor invariance from examples. We show extensive experimental validation, demonstrating the advantage of the proposed approach.
Scale Space and Variational Methods in Computer Vision

The International Conference on Scale Space and Variational Methods in Computer Vision (SSVM 2011) is the third issue of the conference born in 2007 as the joint edition of the Scale-Space Conferences (since 1997, Utrecht) and the Workshop on Variational, Geometric, and Level set Methods (VLSM) that first took place in Vancouver in 2001. Previous issues in Ischia, Italy (2007) and Voss, Norway (2009) were very successful, materializing the hope of the first SSVM organizers, Prof. Sgallari, Murli and Paragios, that the conference would ‘become a reference in the domain’. This year, SSVM was held in Kibbutz Ein-Gedi, Israel – a unique place on the shores of the Dead Sea, the global minimum on earth. Despite its small size, Israel plays an important role on the worldwide scientific arena, and in particular in the fields on computer vision and image processing. Following the tradition of the previous SSVM conferences, we invited outstanding scientists to give keynote presentations. This year, it was our pleasure to welcome Prof. Haim Brezis (Université Pierre et Marie Curie, France), Dr. Remco Duits, (Eindhoven University, The Netherlands), Prof. Stèphane Mallat (École Polytechnique, France), and Prof. Joachim Weickert (Saarland University, Germany). Additionally, we had six review lectures on topics of broad interest, given by experts in the field, Profs. Philip Rosenau (Tel Aviv University, Israel), Jing Yuan (University of Western Ontario, Canada), Patrizio Frosini (University of Bologna, Italy), Radu Horaud (INRIA, France), Gérard Medioni (University of Southern California, USA), and Elisabetta Carlini (La Sapienza, Italy). Out of 78 submitted papers, 24 were selected to be presented orally and 44 as posters. Over 100 people attended the conference, representing countries from all over the world, including Austria, China, France, Germany, Hong-Kong, Israel, Italy, Japan, Korea, the Netherlands, Norway, Singapore, Slovakia, Switzerland, Turkey, and USA. We would like to thank the authors for their contributions, the members of the Program Committee for their dedication and timely review process, and to Yana Katz and Boris Princ for local arrangements and organization without which this conference would not be possible. Finally, our special thanks to the Technion Department of Computer Science, HP Laboratories Israel, Haifa, Rafael Ltd., Israel, BBK Technologies Ltd., Israel, and the European Community’s FP7 ERC/FIRST programs for their generous sponsorship.
Are MSER features really interesting?

Detection and description of affine-invariant features is a cornerstone component in numerous computer vision applications. In this note, we analyze the notion of maximally stable extremal regions (MSER) through the prism of the curvature scale space, and conclude that in its original definition, MSER prefers regular (round) regions. Arguing that interesting features in natural images usually have irregular shapes, we propose alternative definitions of MSER which are free of this bias, yet maintain their invariance properties.
Shape palindromes: analysis of intrinsic symmetries in 2D articulated shapes
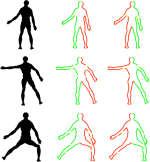
Analysis of intrinsic symmetries of non-rigid and articulated shapes is an important problem in pattern recognition with numerous applications ranging from medicine to computational aesthetics. Considering articulated planar shapes as closed curves, we show how to represent their extrinsic and intrinsic symmetries as self-similarities of local descriptor sequences, which in turn have simple interpretation in the frequency domain. The problem of symmetry detection and analysis thus boils down to analysis of descriptor sequence patterns. For that purpose, we show two efficient computational methods: one based on Fourier analysis, and another on dynamic programming. Metaphorically, the later can be compared to finding palindromes in text sequences.
Intrinsic regularity detection in 3D geometry

Automatic detection of symmetries, regularity, and repetitive structures in 3D geometry is a fundamental problem in shape analysis and pattern recognition with applications in computer vision and graphics. Especially challenging is to detect intrinsic regularity, where the repetitions are on an intrinsic grid, without any apparent Euclidean pattern to describe the shape, but rising out of (near) isometric deformation of the underlying surface. In this paper, we employ multidimensional scaling to reduce the problem of intrinsic structure detection to a simpler problem of 2D grid detection. Potential 2D grids are then identified using an autocorrelation analysis, refined using local fitting, validated, and finally projected back to the spatial domain. We test the detection algorithm on a variety of scanned plaster models in presence of imperfections like missing data, noise and outliers. We also present a range of applications including scan completion, shape editing, super-resolution, and structural correspondence.
Spatially-sensitive affine-invariant image descriptors

Invariant image descriptors play an important role in many computer vision and pattern recognition problems such as image search and retrieval. A dominant paradigm today is that of “bags of features”, a representation of images as distributions of primitive visual elements. The main disadvantage of this approach is the loss of spatial relations between features, which often carry important information about the image. In this paper, we show how to construct spatially-sensitive image descriptors in which both the features and their relation are affine-invariant. Our construction is based on a vocabulary of pairs of features coupled with a vocabulary of invariant spatial relations between the features. Experimental results show the advantage of our approach in image retrieval applications.
Data fusion through cross-modality metric learning using similarity-sensitive hashing
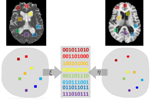
Visual understanding is often based on measuring similarity between observations. Learning similarities specific to a certain perception task from a set of examples has been shown advantageous in various computer vision and pattern recognition problems. In many important applications, the data that one needs to compare come from different representations or modalities, and the similarity between such data operates on objects that may have different and often incommensurable structure and dimensionality. In this paper, we propose a framework for supervised similarity learning based on embedding the input data from two arbitrary spaces into the Hamming space. The mapping is expressed as a binary classification problem with positive and negative examples, and can be efficiently learned using boosting algorithms. The utility and efficiency of such a generic approach is demonstrated on several challenging applications including cross-representation shape retrieval and alignment of multi-modal medical images.
ShapeGoogle: a computer vision approach for invariant shape retrieval

Feature-based methods have recently gained popularity in computer vision and pattern recognition communities, in applications such as object recognition and image retrieval. In this paper, we explore analogous approaches in the 3D world applied to the problem of non-rigid shape search and retrieval in large databases.
On reconstruction of non-rigid shapes with intrinsic regularization

Shape-from-X is a generic type of inverse problems in computer vision, in which a shape is reconstructed from some measurements. A specially challenging setting of this problem is the case in which the reconstructed shapes are non-rigid. In this paper, we propose a framework for intrinsic regularization of such problems. The assumption is that we have the geometric structure of a shape which is intrinsically (up to bending) similar to the one we would like to reconstruct. For that goal, we formulate a variation with respect to vertex coordinates of a triangulated mesh approximating the continuous shape. The numerical core of the proposed method is based on differentiating the fast marching update step for geodesic distance computation.
Partial similarity of objects, or how to compare a centaur to a horse
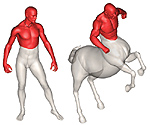
Similarity is one of the most important abstract concepts in human perception of the world. In computer vision, numerous applications deal with comparing objects observed in a scene with some a priori known patterns. Often, it happens that while two objects are not similar, they have large similar parts, that is, they are partially similar. Here, we present a novel approach to quantify partial similarity using the notion of Pareto optimality. We exemplify our approach on the problems of recognizing non-rigid geometric objects, images, and analyzing text sequences.
Analysis of two-dimensional non-rigid shapes

Analysis of deformable two-dimensional shapes is an important problem, encountered in numerous pattern recognition, computer vision, and computer graphics applications. In this paper, we address three major problems in the analysis of non-rigid shapes: similarity, partial similarity, and correspondence. We present an axiomatic construction of similarity criteria for deformation-invariant shape comparison, based on intrinsic geometric properties of the shapes, and show that such criteria are related to the Gromov-Hausdorff distance. Next, we extend the problem of similarity computation to shapes which have similar parts but are dissimilar when considered as a whole and present a construction of set-valued distances, based on the notion of Pareto optimality. Finally, we show that the correspondence between non-rigid shapes can be obtained as a byproduct of the non-rigid similarity problem. As a numerical framework, we use the generalized multidimensional scaling (GMDS) method, which is the numerical core of the three problems addressed in this paper.
Rock, Paper, and Scissors: extrinsic vs. intrinsic similarity of non-rigid shapes

This paper explores similarity criteria between non-rigid shapes. Broadly speaking, such criteria are divided into intrinsic and extrinsic, the first referring to the metric structure of the objects and the latter to the geometry of the shapes in the Euclidean space. Both criteria have their advantages and disadvantages; extrinsic similarity is sensitive to non-rigid deformations of the shapes, while intrinsic similarity is sensitive to topological noise. Here, we present an approach unifying both criteria in a single distance. Numerical results demonstrate the robustness of our approach in cases where using only extrinsic or intrinsic criteria fail.
Partial similarity of objects and text sequences
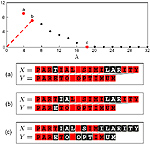
Similarity is one of the most important abstract concepts in the human perception of the world. In computer vision, numerous applications deal with comparing objects observed in a scene with some a priori known patterns. Often, it happens that while two objects are not similar, they have large similar parts, that is, they are partially similar. Here, we present a novel approach to quantify this semantic definition of partial similarity using the notion of Pareto optimality. We exemplify our approach on the problems of recognizing non-rigid objects and analyzing text sequences.
Expression-invariant representation of faces
We present an efficient computational framework for isometry-invariant comparison of smooth surfaces. We formulate the Gromov-Hausdorff distance as a multidimensional scaling (MDS)-like continuous optimization problem. In order to construct an efficient optimization scheme, we develop a numerical tool for interpolating geodesic distances on a sampled surface from precomputed geodesic distances between the samples. For isometry-invariant comparison of surfaces in the case of partially missing data, we present the partial embedding distance, which is computed using a similar scheme. The main idea is finding a minimum-distortion mapping from one surface to another while considering only relevant geodesic distances. We discuss numerical implementation issues and present experimental results that demonstrate its accuracy and efficiency.
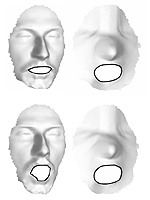
Robust expression-invariant face recognition from partially missing data
Recent studies on three-dimensional face recognition proposed to model facial expressions as isometries of the facial surface. Based on this model, expression-invariant signatures of the face were constructed by means of approximate isometric embedding into flat spaces. Here, we apply a new method for measuring isometry-invariant similarity between faces by embedding one facial surface into another. We demonstrate that our approach has several significant advantages, one of which is the ability to handle partially missing data. Promising face recognition results are obtained in numerical experiments even when the facial surfaces are severely occluded.
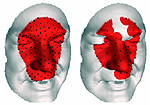
Matching two-dimensional articulated shapes using generalized multidimensional scaling
We present a theoretical and computational framework for matching of two-dimensional articulated shapes. Assuming that articulations can be modeled as near-isometries, we show an axiomatic construction of an articulation-invariant distance between shapes, formulated as a generalized multidimensional scaling (GMDS) problem and solved efficiently. Some numerical results demonstrating the accuracy of our method are presented.
Multigrid multidimensional scaling

Multidimensional scaling (MDS) is a generic name for a family of algorithms that construct a configuration of points in a target metric space from information about inter-point distances measured in some other metric space. Large-scale MDS problems often occur in data analysis, representation, and visualization. Solving such problems efficiently is of key importance in many applications. In this paper, we present a multigrid framework for MDS problems. We demonstrate the performance of our algorithm on dimensionality reduction and isometric embedding problems, two classical problems requiring efficient large-scale MDS. Simulation results show that the proposed approach significantly outperforms conventional MDS algorithms.
Three-dimensional face recognition

An expression-invariant 3D face recognition approach is presented. Our basic assumption is that facial expressions can be modeled as isometries of the facial surface. This allows to construct expression-invariant representations of faces using the canonical forms approach. The result is an efficient and accurate face recognition algorithm, robust to facial expressions that can distinguish between identical twins (the first two authors). We demonstrate a prototype system based on the proposed algorithm and compare its performance to classical face recognition methods. The numerical methods employed by our approach do not require the facial surface explicitly. The surface gradients field, or the surface metric, are sufficient for constructing the expression-invariant representation of any given face. It allows us to perform the 3D face recognition task while avoiding the surface reconstruction stage.
Expression-invariant face recognition via spherical embedding
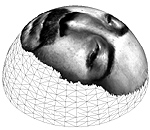
Recently, it was proven empirically that facial expressions can be modeled as isometries, that is, geodesic distances on the facial surface were shown to be significantly less sensitive to facial expressions compared to Euclidean ones. Based on this assumption, the 3DFACE face recognition system was built. The system efficiently computes expression invariant signatures based on an isometry-invariant representation of the facial surface. One of the crucial steps in the recognition system was embedding of the face geometric structure into a Euclidean (flat) space. Here, we propose to replace the flat embedding by a spherical one to construct isometric invariant representations of the facial image. We refer to these new invariants as spherical canonical images. Compared to its Euclidean counterpart, spherical embedding leads to notably smaller metric distortion. We demonstrate experimentally that representations with lower embedding error lead to better recognition. In order to efficiently compute the invariants, we introduce a dissimilarity measure between the spherical canonical images based on the spherical harmonic transform.
Fusion of 2D and 3D data in three-dimensional face recognition

We discuss the synthesis between the 3D and the 2D data in three-dimensional face recognition. We show how to compensate for the illumination and facial expressions using the 3D facial geometry and present the approach of canonical images, which allows to incorporate geometric information into standard face recognition approaches.
Face recognition from facial surface metric

Recently, a 3D face recognition approach based on geometric invariant signatures, has been proposed. The key idea is a representation of the facial surface, invariant to isometric deformations, such as those resulting from facial expressions. One important stage in the construction of the geometric invariants involves in measuring geodesic distances on triangulated surfaces, which is carried out by the fast marching on triangulated domains algorithm. Proposed here is a method that uses only the metric tensor of the surface for geodesic distance computation. That is, the explicit integration of the surface in 3D from its gradients is not needed for the recognition task. It enables the use of simple and cost-efficient 3D acquisition techniques such as photometric stereo. Avoiding the explicit surface reconstruction stage saves computational time and reduces numerical errors.
Expression-invariant 3D face recognition

We present a novel 3D face recognition approach based on geometric invariants introduced by Elad and Kimmel. The key idea of the proposed algorithm is a representation of the facial surface, invariant to isometric deformations, such as those resulting from different expressions and postures of the face. The obtained geometric invariants allow mapping 2D facial texture images into special images that incorporate the 3D geometry of the face. These signature images are then decomposed into their principal components. The result is an efficient and accurate face recognition algorithm that is robust to facial expressions. We demonstrate the results of our method and compare it to existing 2D and 3D face recognition algorithms.
Iterative reconstruction in diffraction tomography using non-uniform fast Fourier transform
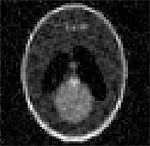
We show an iterative reconstruction framework for diffraction ultrasound tomography. The use of broadband illumination allows the number of projections to be reduced significantly compared to straight ray tomography. The proposed algorithm makes use of fast forward non-uniform Fourier transform (NUFFT) for iterative Fourier inversion. Incorporation of total variation regularization allows noise and Gibbs phenomena to be reduced whilst preserving the edges.