
Relevant publications
Signal & Image Processing
Automatic identification and visualization of group training activities using wearable data

Human Activity Recognition (HAR) identifies daily activities from time-series data collected by wearable devices like smartwatches. Recent advancements in Internet of Things (IoT), cloud computing, and low-cost sensors have broadened HAR applications across fields like healthcare, biometrics, sports, and personal fitness. However, challenges remain in efficiently processing the vast amounts of data generated by these devices and developing models that can accurately recognize a wide range of activities from continuous recordings, without relying on predefined activity training sessions. This paper presents a comprehensive framework for imputing, analyzing, and identifying activities from wearable data, specifically targeting group training scenarios without explicit activity sessions. Our approach is based on data collected from 135 soldiers wearing Garmin 55 smartwatches over six months. The framework integrates multiple data streams, handles missing data through cross-domain statistical methods, and identifies activities with high accuracy using machine learning (ML). Additionally, we utilized statistical analysis techniques to evaluate the performance of each individual within the group, providing valuable insights into their respective positions in the group in an easy-to-understand visualization. These visualizations facilitate easy understanding of performance metrics, enhancing group interactions and informing individualized training programs. We evaluate our framework through traditional train-test splits and out-of-sample scenarios, focusing on the model’s generalization capabilities. Additionally, we address sleep data imputation without relying on ML, improving recovery analysis. Our findings demonstrate the potential of wearable data for accurately identifying group activities, paving the way for intelligent, data-driven training solutions.
Beyond the alphabet: deep signal embedding for enhanced DNA clustering
The emerging field of DNA storage employs strands of DNA bases (A/T/C/G) as a storage medium for digital information to enable massive density and durability. The DNA storage pipeline includes: (1) encoding the raw data into sequences of DNA bases; (2) synthesizing the sequences as DNA strands that are stored over time as an unordered set; (3) sequencing the DNA strands to generate DNA reads; and (4) deducing the original data. The DNA synthesis and sequencing stages each generate several independent error-prone duplicates of each strand which are then utilized in the final stage to reconstruct the best estimate for the original strand. Specifically, the reads are first clustered into groups likely originating from the same strand (based on their similarity to each other), and then each group approximates the strand that led to the reads of that group. This work improves the DNA clustering stage by embedding it as part of the DNA sequencing. Traditional DNA storage solutions begin after the DNA sequencing process generates discrete DNA reads (A/T/C/G), yet we identify that there is untapped potential in using the raw signals generated by the Nanopore DNA sequencing machine before they are discretized into bases, a process known as basecalling, which is done using a deep neural network. We propose a deep neural network that clusters these signals directly, demonstrating superior accuracy, and reduced computation times compared to current approaches that cluster after basecalling.
Data-driven cellular network selector for vehicle teleoperations
Remote control of robotic systems, also known as teleoperation, is crucial for the development of autonomous vehicle (AV) technology. It allows a remote operator to view live video from AVs and, in some cases, to make real-time decisions. The effectiveness of video-based teleoperation systems is heavily influenced by the quality of the cellular network and, in particular, its packet loss rate and latency. To optimize these parameters, an AV can be connected to multiple cellular networks and determine in real time over which cellular network each video packet will be transmitted. We present an algorithm, called Active Network Selector (ANS), which uses a time series machine learning approach for solving this problem. We compare ANS to a baseline non-learning algorithm, which is used today in commercial systems, and show that ANS performs much better, with respect to both packet loss and packet latency.
Data-driven modeling of interrelated dynamical systems
Non-linear dynamical systems describe numerous real-world phenomena, ranging from the weather, to financial markets and disease progression. Individual systems may share substantial common information, for example patients’ anatomy. Lately, deep-learning has emerged as a leading method for data-driven modeling of non-linear dynamical systems. Yet, despite recent breakthroughs, prior works largely ignored the existence of shared information between different systems. However, such cases are quite common, for example, in medicine: we may wish to have a patient-specific model for some disease, but the data collected from a single patient is usually too small to train a deep-learning model. Hence, we must properly utilize data gathered from other patients. Here, we explicitly consider such cases by jointly modeling multiple systems. We show that the current single-system models consistently fail when trying to learn simultaneously from multiple systems. We suggest a framework for jointly approximating the Koopman operators of multiple systems, while intrinsically exploiting common information. We demonstrate how we can adapt to a new system using order-of-magnitude less new data and show the superiority of our model over competing methods, in terms of both forecasting ability and statistical fidelity, across chaotic, cardiac, and climate systems.
Active propulsion noise shaping for multi-rotor aircraft localization
Multi-rotor aerial autonomous vehicles (MAVs) primarily rely on vision for navigation purposes. However, visual localization and odometry techniques suffer from poor performance in low or direct sunlight, a limited field of view, and vulnerability to occlusions. Acoustic sensing can serve as a complementary or even alternative modality for vision in many situations, and it also has the added benefits of lower system cost and energy footprint, which is especially important for micro aircraft. This paper proposes actively controlling and shaping the aircraft propulsion noise generated by the rotors to benefit localization tasks, rather than considering it a harmful nuisance. We present a neural network architecture for selfnoise-based localization in a known environment. We show that training it simultaneously with learning time-varying rotor phase modulation achieves accurate and robust localization. The proposed methods are evaluated using a computationally affordable simulation of MAV rotor noise in 2D acoustic environments that is fitted to real recordings of rotor pressure fields.
ISP distillation
Nowadays, many of the images captured are ‘observed’ by machines only and not by humans, e.g., in autonomous systems. High-level machine vision models, such as object recognition or semantic segmentation, assume images are transformed into some canonical image space by the camera Image Signal Processor (ISP). However, the camera ISP is optimized for producing visually pleasing images for human observers and not for machines. Therefore, one may spare the ISP compute time and apply vision models directly to RAW images. Yet, it has been shown that training such models directly on RAW images results in a performance drop. To mitigate this drop, we use a RAW and RGB image pairs dataset, which can be easily acquired with no human labeling. We then train a model that is applied directly to the RAW data by using knowledge distillation such that the model predictions for RAW images will be aligned with the predictions of an off-the-shelf pre-trained model for processed RGB images. Our experiments show that our performance on RAW images for object classification and semantic segmentation is significantly better than models trained on labeled RAW images. It also reasonably matches the predictions of a pre-trained model on processed RGB images, while saving the ISP compute overhead.
Designing nonlinear photonic crystals for high-dimensional quantum state engineering
We propose a novel, physically-constrained and differentiable approach for the generation of D-dimensional qudit states via spontaneous parametric downconversion (SPDC) in quantum optics. We circumvent any limitations imposed by the inherently stochastic nature of the physical process and incorporate a set of stochastic dynamical equations governing its evolution under the SPDC Hamiltonian. We demonstrate the effectiveness of our model through the design of
structured nonlinear photonic crystals (NLPCs) and shaped pump beams; and show, theoretically and experimentally, how to generate maximally entangled states in the spatial degree of freedom. The learning of NLPC structures offers a promising new avenue for shaping and controlling arbitrary quantum states and enables all-optical coherent control of the generated states. We believe that this approach can readily be extended from bulky crystals to thin Metasurfaces and potentially applied to other quantum systems sharing a similar Hamiltonian structures, such as superfluids and superconductors.
A machine learning approach to generate quantum light
Spontaneous parametric down-conversion (SPDC) is a key technique in quantum optics used to generate entangled photon pairs. However, generating a desirable D-dimensional qudit state in the SPDC process remains a challenge. In this paper, we introduce a physically-constrained and differentiable model to overcome this challenge, and demonstrate its effectiveness through the design of shaped pump beams and structured nonlinear photonic crystals. We avoid any restrictions induced by the stochastic nature of our physical process and integrate a set of stochastic dynamical equations governing its evolution under the SPDC Hamiltonian. Our model is capable of learning the relevant interaction parameters and designing nonlinear quantum optical systems that achieve desired quantum states. We show, theoretically and experimentally, how to generate maximally entangled states in the spatial degree of freedom. Additionally, we demonstrate all-optical coherent control of the generated state by reshaping the pump beam. Our work has potential applications in high-dimensional quantum key distribution and quantum information processing.
Fast nonlinear vector quantile regression
Quantile regression (QR) is a powerful tool for estimating one or more conditional quantiles of a target variable Y given explanatory features X. A limitation of QR is that it is only defined for scalar target variables, due to the formulation of its objective function, and since the notion of quantiles has no standard definition for multivariate distributions. Recently, vector quantile regression (VQR) was proposed as an extension of QR for high-dimensional target variables, thanks to a meaningful generalization of the notion of quantiles to multivariate distributions. Despite its elegance, VQR is arguably not applicable in practice due to several limitations: (i) it assumes a linear model for the quantiles of the target Y given the features X; (ii) its exact formulation is intractable even for modestly-sized problems in terms of target dimensions, the number of regressed quantile levels, or the number of features, and its relaxed dual formulation may violate the monotonicity of the estimated quantiles; (iii) no fast or scalable solvers for VQR currently exist. In this work we fully address these limitations, namely: (i) We extend VQR to the non-linear case, showing substantial improvement over linear VQR; (ii) We propose vector monotone rearrangement, a method which ensures the estimates obtained by VQR relaxations are monotone functions; (iii) We provide fast, GPU-accelerated solvers for linear and nonlinear VQR which maintain a fixed memory footprint with the number of samples and quantile levels, and demonstrate that they scale to millions of samples and thousands of quantile levels; (iv) We release an optimized python package of our solvers as to widespread the use of VQR in real-world applications.
Using deep reinforcement learning for mmWave real-time scheduling
We study the problem of real-time scheduling in a multi-hop millimeter-wave (mmWave) mesh. We develop a model-free deep reinforcement learning algorithm called Adaptive Activator RL (AARL), which determines the subset of mmWave links that should be activated during each time slot and the power level for each link. The most important property of AARL is its ability to make scheduling decisions within the strict time slot constraints of typical 5G mmWave networks. AARL can handle a variety of network topologies, network loads, and interference models, it can also adapt to different workloads. We demonstrate the operation of AARL on several topologies: a small topology with 10 links, a moderately-sized mesh with 48 links, and a large topology with 96 links. We show that for each topology, we compare the throughput obtained by AARL to that of a benchmark algorithm called RPMA (Residual Profit Maximizer Algorithm). The most important advantage of AARL compared to RPMA is that it is much faster and can make the necessary scheduling decisions very rapidly during every time slot, while RPMA cannot. In addition, the quality of the scheduling decisions made by AARL outperforms those made by RPMA.
Inverse design of spontaneous parametric downconversion for generation of high-dimensional qudits
Spontaneous parametric down-conversion in quantum optics is an invaluable resource for the realization of high-dimensional qudits with spatial modes of light. One of the main open challenges is how to directly generate a desirable qudit state in the SPDC process. This problem can be addressed through advanced computational learning methods; however, due to difficulties in modeling the SPDC process by a fully differentiable algorithm that takes into account all interaction effects, progress has been limited. Here, we overcome these limitations and introduce a physically-constrained and differentiable model, validated against experimental results for shaped pump beams and structured crystals, capable of learning every interaction parameter in the process. We avoid any restrictions induced by the stochastic nature of our physical model and integrate the dynamic equations governing the evolution under the SPDC Hamiltonian. We solve the inverse problem of designing a nonlinear quantum optical system that achieves the desired quantum state of down-converted photon pairs. The desired states are defined using either the second-order correlations between different spatial modes or by specifying the required density matrix. By learning nonlinear volume holograms as well as different pump shapes, we successfully show how to generate maximally entangled states. Furthermore, we simulate all-optical coherent control over the generated quantum state by actively changing the profile of the pump beam. Our work can be useful for applications such as novel designs of high-dimensional quantum key distribution and quantum information processing protocols. In addition, our method can be readily applied for controlling other degrees of freedom of light in the SPDC process, such as the spectral and temporal properties, and may even be used in condensed-matter systems having a similar interaction Hamiltonian.
Self-Supervised Object Detection and Retrieval Using Unlabeled Videos
Unlabeled video in the wild presents a valuable, yet so far unharnessed, source of information for learning vision tasks. We present the first attempt of fully self-supervised learning of object detection from subtitled videos without any manual object annotation. To this end, we use the How2 multi-modal collection of instructional videos with English subtitles. We pose the problem as learning with a weakly- and noisily-labeled data, and propose a novel training model that can confront high noise levels, and yet train a classifier to localize the object of interest in the video frames, without any manual labeling involved. We evaluate our approach on a set of 11 manually annotated objects in over 5000 frames and compare it to an existing weakly-supervised approach as baseline. Benchmark data and code will be released upon acceptance of the paper.
Over-parameterized models for vector fields
Vector fields arise in a variety of quantity measure and visualization techniques such as fluid flow imaging, motion estimation, deformation measures, and color imaging, leading to a better understanding of physical phenomena. Recent progress in vector field imaging technologies has emphasized the need for efficient noise removal and reconstruction algorithms. A key ingredient in the success of extracting signals from noisy measurements is prior information, which can often be represented as a parameterized model. In this work, we extend the over-parameterization variational framework in order to perform model-based reconstruction of vector fields. The over-parameterization methodology combines local modeling of the data with global model parameter regularization. By considering the vector field as a linear combination of basis vector fields and appropriate scale and rotation coefficients, the denoising problem reduces to a simpler form of coefficient recovery. We introduce two versions of the over-parameterization framework: total variation-based method and sparsity-based method, relying on the co-sparse analysis model. We demonstrate the efficiency of the proposed frameworks for two- and three-dimensional vector fields with linear and quadratic over-parameterization models.
Deep matrix factorization with spectral geometric regularization
We address the problem of reconstructing a matrix from a subset of its entries. Current methods, branded as geometric matrix completion, augment classical rank regularization techniques by incorporating geometric information into the solution. This information is usually provided as graphs encoding relations between rows/columns. In this work, we propose a simple spectral approach for solving the matrix completion problem, via the framework of functional maps. We introduce the zoomout loss, a multiresolution spectral geometric loss inspired by recent advances in shape correspondence, whose minimization leads to state-of-the-art results on various recommender systems datasets. Surprisingly, for some datasets, we were able to achieve comparable results even without incorporating geometric information. This puts into question both the quality of such information and current methods’ ability to use it in a meaningful and efficient way.
Code is available either as Google Colab notebook, or via https://github.com/amitboy/SGMC
Learning beamforming in ultrasound imaging
LaSO: Label-Set Operations networks for multi-label few-shot learning
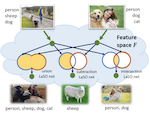
Example synthesis is one of the leading methods to tackle the problem of few-shot learning, where only a small number of samples per class are available. However, current synthesis approaches only address the scenario of a single category label per image. In this work, we propose a novel technique for synthesizing samples with multiple labels for the (yet unhandled) multi-label few-shot classification scenario. We propose to combine pairs of given examples in feature space, so that the resulting synthesized feature vectors will correspond to examples whose label sets are obtained through certain set operations on the label sets of the corresponding input pairs. Thus, our method is capable of producing a sample containing the intersection, union or set-difference of labels present in two input samples. As we show, these set operations generalize to labels unseen during training. This enables performing augmentation on examples of novel categories, thus, facilitating multi-label few-shot classifier learning. We conduct numerous experiments showing promising results for the label-set manipulation capabilities of the proposed approach, both directly (using the classification and retrieval metrics), and in the context of performing data augmentation for multi-label few-shot learning. We propose a benchmark for this new and challenging task and show that our method compares favorably to all the common baselines.
Beholder-GAN: Generation and beautification of facial images with conditioning on their beauty level

Beauty is in the eye of the beholder. This maxim, emphasizing the subjectivity of the perception of beauty, has enjoyed a wide consensus since ancient times. In the digital era, data-driven methods have been shown to be able to predict human-assigned beauty scores for facial images. In this work, we augment this ability and train a generative model that generates faces conditioned on a requested beauty score. In addition, we show how this trained generator can be used to beautify an input face image. By doing so, we achieve an unsupervised beautification model, in the sense that it relies on no ground truth target images.
Class-aware fully-convolutional Gaussian and Poisson denoising

We propose a fully-convolutional neural-network architecture for image denoising which is simple yet powerful. Its structure allows to exploit the gradual nature of the denoising process, in which shallow layers handle local noise statistics, while deeper layers recover edges and enhance textures. Our method advances the state-of-the-art when trained for different noise levels and distributions (both Gaussian and Poisson). In addition, we show that making the denoiser class-aware by exploiting semantic class information boosts performance, enhances textures and reduces artifacts.
DeepISP: Towards learning an end-to-end image processing pipeline

We present DeepISP, a full end-to-end deep neural model of the camera image signal processing (ISP) pipeline. Our model learns a mapping from the raw low-light mosaiced image to the final visually compelling image and encompasses low-level tasks such as demosaicing and denoising as well as higher-level tasks such as color correction and image adjustment. The training and evaluation of the pipeline were performed on a dedicated dataset containing pairs of low-light and well-lit images captured by a Samsung S7 smartphone camera in both raw and processed JPEG formats. The proposed solution achieves state-of-the-art performance in the objective evaluation of PSNR on the subtask of joint denoising and demosaicing. For the full end-to-end pipeline, it achieves better visual quality compared to the manufacturer ISP, in both a subjective human assessment and when rated by a deep model trained for assessing image quality.
Tradeoffs between convergence speed and reconstruction accuracy in inverse problems
Solving inverse problems with iterative algorithms is popular, especially for large data. Due to time constraints, the number of possible iterations is usually limited, potentially affecting the achievable accuracy. Given an error one is willing to tolerate, an important question is whether it is possible to modify the original iterations to obtain faster convergence to a minimizer achieving the allowed error without increasing the computational cost of each iteration considerably. Relying on recent recovery techniques developed for settings in which the desired signal belongs to some low-dimensional set, we show that using a coarse estimate of this set may lead to faster convergence at the cost of an additional reconstruction error related to the accuracy of the set approximation. Our theory ties to recent advances in sparse recovery, compressed sensing, and deep learning. Particularly, it may provide a possible explanation to the successful approximation of the L1-minimization solution by neural networks with layers representing iterations, as practiced in the learned iterative shrinkage-thresholding algorithm.
Deep class-aware image denoising

The increasing demand for high image quality in mobile devices brings forth the need for better computational enhancement techniques, and image denoising in particular. To this end, we propose a new fully convolutional deep neural network architecture which is simple yet powerful and achieves state-of-the-art performance for additive Gaussian noise removal. Furthermore, we claim that the personal photo-collections can usually be categorized into a small set of semantic classes. However simple, this observation has not been exploited in image denoising until now. We show that a significant boost in performance of up to 0.4dB PSNR can be achieved by making our network class-aware, namely, by fine-tuning it for images belonging to a specific semantic class. Relying on the hugely successful existing image classifiers, this research advocates for using a class-aware approach in all image enhancement tasks.
Cloud Dictionary: Sparse coding and modeling for point clouds
With the development of range sensors such as LIDAR and time-of-flight cameras, 3D point cloud scans have become ubiquitous in computer vision applications, the most prominent ones being gesture recognition and autonomous driving. Parsimony-based algorithms have shown great success on images and videos where data points are sampled on a regular Cartesian grid. We propose an adaptation of these techniques to irregularly sampled signals by using continuous dictionaries. We present an example application in the form of point cloud denoising.
Deep class-aware denoising
The increasing demand for high image quality in mobile devices brings forth the need for better computational enhancement techniques, and image denoising in particular. At the same time, the images captured by these devices can be categorized into a small set of semantic classes. However simple, this observation has not been exploited in image denoising until now. In this paper, we demonstrate how the reconstruction quality improves when a denoiser is aware of the type of content in the image. To this end, we first propose a new fully convolutional deep neural network architecture which is simple yet powerful as it achieves state-of-the-art performance even without be- ing class-aware. We further show that a significant boost in performance of up to 0.4 dB PSNR can be achieved by making our network class-aware, namely, by fine-tuning it for images belonging to a specific semantic class. Relying on the hugely successful existing image classifiers, this research advocates for using a class-aware approach in all image enhancement tasks.
Deep convolutional denoising of low-light images
Poisson distribution is used for modeling noise in photon-limited imaging. While canonical examples include relatively exotic types of sensing like spectral imaging or astronomy, the problem is relevant to regular photography now more than ever due to the booming market for mobile cameras. Restricted form factor limits the amount of absorbed light, thus computational post-processing is called for. In this paper, we make use of the powerful framework of deep convolutional neural networks for Poisson denoising. We demonstrate how by training the same network with images having a specific peak value, our denoiser outperforms previous state-of-the-art by a large margin both visually and quantitatively. Being flexible and data-driven, our solution resolves the heavy ad hoc engineering used in previous methods and is an order of magnitude faster. We further show that by adding a reasonable prior on the class of the image being processed, another significant boost in performance is achieved.
FPGA system for real-time computational extended depth of field imaging using phase aperture coding
We present a proof-of-concept end-to-end system for computational extended depth of field (EDOF) imaging. The acquisition is performed through a phase-coded aperture implemented by placing a thin wavelength-dependent op- tical mask inside the pupil of a conventional camera lens, as a result of which, each color channel is focused at a different depth. The reconstruction process re- ceives the raw Bayer image as the input, and performs blind estimation of the output color image in focus at an extended range of depths using a patch-wise sparse prior. We present a fast non-iterative reconstruction algorithm operating with constant latency in fixed-point arithmetics and achieving real-time perfor- mance in a prototype FPGA implementation. The output of the system, on simu- lated and real-life scenes, is qualitatively and quantitatively better than the result of clear-aperture imaging followed by state-of-the-art blind deblurring.
Sparsity and nullity: paradigms for analysis dictionary learning

Sparse models in dictionary learning have been successfully applied in a wide variety of machine learning and computer vision problems, and as a result, have recently attracted increased research interest. Another interesting related problem based on linear equality constraints, namely the sparse null space (SNS) problem, first appeared in 1986 and has since inspired results on sparse basis pursuit. In this paper, we investigate the relation between the SNS problem and the analysis dictionary learning (ADL) problem, and show that the SNS problem plays a central role, and may be utilized to solve dictionary learning problems. Moreover, we propose an efficient algorithm of sparse null space basis pursuit (SNS-BP) and extend it to a solution of ADL. Experimental results on numerical synthetic data and real-world data are further presented to validate the performance of our method.
Multimodal manifold analysis using simultaneous diagonalization of Laplacians
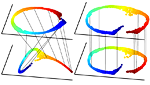
We construct an extension of spectral and diffusion geometry to multiple modalities through simultaneous diagonalization of Laplacian matrices. This naturally extends classical data analysis tools based on spectral geometry, such as diffusion maps and spectral clustering. We provide several synthetic and real examples of manifold learning, retrieval, and clustering demonstrating that the joint spectral geometry frequently better captures the inherent structure of multi-modal data. We also show the relation of many previous approaches to multimodal manifold analysis to our framework, of which the can be seen as particular cases.
A Picture is Worth a Billion Bits: Real-time image reconstruction from dense binary pixels
The pursuit of smaller pixel sizes at ever-increasing resolution in digital image sensors is mainly driven by the stringent price and form-factor requirements of sensors and optics in the cellular phone market. Recently, Eric Fossum proposed a novel concept of an image sensor with dense sub-diffraction limit one-bit pixels (jots), which can be considered a digital emulation of silver halide photographic film. This idea has been recently embodied as the EPFL Gigavision camera. A major bottleneck in the design of such sensors is the image reconstruction process, producing a continuous high dynamic range image from oversampled bi- nary measurements. The extreme quantization of the Pois- son statistics is incompatible with the assumptions of most standard image processing and enhancement frameworks. The recently proposed maximum-likelihood (ML) approach addresses this difficulty, but suffers from image artifacts and has impractically high computational complexity. In this work, we study a variant of a sensor with binary thresh- old pixels and propose a reconstruction algorithm combin- ing an ML data fitting term with a sparse synthesis prior. We also show an efficient hardware-friendly real-time approximation of this inverse operator. Promising results are shown on synthetic data as well as on HDR data emulated using multiple exposures of a regular CMOS sensor.
Computational all-in-focus imaging using an optical phase mask

A method for extended depth of field imaging based on image acquisition through a thin binary phase plate followed by fast automatic computational post-processing is presented. By placing a wavelength dependent optical mask inside the pupil of a conventional camera lens, one acquires a unique response for each of the three main color channels, which adds valuable information that allows blind reconstruction of blurred images without the need of an iterative search process for estimating the blurring kernel. The presented simulation as well as capture of a real life scene show how acquiring a one-shot image focused at a single plane, enable generating a de-blurred scene over an extended range in space.
Sparse null space basis pursuit and analysis dictionary learning for high-dimensional data analysis
Sparse models in dictionary learning have been successfully applied in a wide variety of machine learning and computer vision problems, and have also recently been of increasing research interest. Another interesting related problem based on a linear equality constraint, namely the sparse null space problem (SNS), first appeared in 1986, and has since inspired results on sparse basis pursuit. In this paper, we investigate the relation between the SNS problem and the analysis dictionary learning problem, and show that the SNS problem plays a central role, and may be utilized to solve dictionary learning problems. Moreover, we propose an efficient algorithm of sparse null space basis pursuit, and extend it to a solution of analysis dictionary learning. Experimental results on numerical synthetic data and realworld data are further presented to validate the performance of our method.
Learning efficient sparse and low-rank models

Parsimony, including sparsity and low rank, has been shown to successfully model data in numerous machine learning and signal processing tasks. Traditionally, parsimonious modeling approaches rely on an iterative algorithm that minimizes an objective function with parsimony-promoting terms. The inherently sequential structure and data-dependent complexity and latency of iterative optimization constitute a major limitation in many applications requiring real-time performance or involving large-scale data. Another limitation encountered by these models is the difficulty of their inclusion in supervised learning scenarios, where the higher-level training objective would depend on the solution of the lower-level pursuit problem. The resulting bilevel optimization problems are in general notoriously difficult to solve. In this paper, we propose to move the emphasis from the model to the pursuit algorithm, and develop a process-centric view of parsimonious modeling, in which a deterministic fixed-complexity pursuit process is used in lieu of iterative optimization. We show a principled way to construct learnable pursuit process architectures for structured sparse and robust low rank models from the iteration of proximal descent algorithms. These architectures approximate the exact parsimonious representation with a fraction of the complexity of the standard optimization methods. We also show that carefully chosen training regimes allow to naturally extend parsimonious models to discriminative settings. State-of-the-art results are demonstrated on several challenging problems in image and audio processing with several orders of magnitude speedup compared to the exact optimization algorithms.
Supervised non-negative matrix factorization for audio source separation
Source separation is a widely studied problems in signal processing. Despite the permanent progress reported in the literature it is still considered a significant challenge. This chapter first reviews the use of non-negative matrix factorization (NMF) algorithms for solving source separation problems, and proposes a new way for the supervised training in NMF. Matrix factorization methods have received a lot of attention in recent year in the audio processing community, producing particularly good results in source separation. Traditionally, NMF algorithms consist of two separate stages: a training stage, in which a generative model is learned; and a testing stage in which the pre-learned model is used in a high level task such as enhancement, separation, or classification. As an alternative, we propose a tasksupervised NMF method for the adaptation of the basis spectra learned in the first stage to enhance the performance on the specific task used in the second stage. We cast this problem as a bilevel optimization program efficiently solved via stochastic gradient descent. The proposed approach is general enough to handle sparsity priors of the activations, and allow non-Euclidean data terms such as beta-divergences. The framework is evaluated on speech enhancement.
Supervised non-Euclidean sparse NMF via bilevel optimization with applications to speech enhancement
Traditionally, NMF algorithms consist of two separate stages: a training stage, in which a generative model is learned; and a testing stage in which the pre-learned model is used in a high level task such as enhancement, separation, or classification. As an alternative, we propose a task-supervised NMF method for the adaptation of the basis spectra learned in the first stage to enhance the performance on the specific task used in the second stage. We cast this problem as a bilevel optimization program that can be efficiently solved via stochastic gradient descent. The proposed approach is general enough to handle sparsity priors of the activations, and allow non-Euclidean data terms such as beta-divergences. The framework is evaluated on single-channel speech enhancement tasks.
Real-time compressed imaging of scattering volumes

We propose a method and a prototype imaging system for real-time reconstruction of volumetric piecewise-smooth scattering media. The volume is illuminated by a sequence of structured binary patterns emitted from a fan beam projector, and the scattered light is collected by a two-dimensional sensor, thus creating an under-complete set of compressed measurements. We show a fixed-complexity and latency reconstruction algorithm capable of estimating the scattering coefficients in real-time. We also show a simple greedy algorithm for learning the optimal illumination patterns. Our results demonstrate faithful reconstruction from highly compressed measurements. Furthermore, a method for compressed registration of the measured volume to a known template is presented, showing excellent alignment with just a single projection. Though our prototype system operates in visible light, the presented methodology is suitable for fast x-ray scattering imaging, in particular in real-time vascular medical imaging.
Efficient supervised sparse analysis and synthesis operators
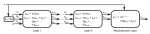
In this paper, we propose a new and computationally efficient framework for learning sparse models. We formulate a unified approach that contains as particular cases models promoting sparse synthesis and analysis type of priors, and mixtures thereof. The supervised training of the proposed model is formulated as a bilevel optimization problem, in which the operators are optimized to achieve the best possible performance on a specific task, e.g., reconstruction or classification. By restricting the operators to be shift invariant, our approach can be thought as a way of learning analysis+synthesis sparsity-promoting convolutional operators. Leveraging recent ideas on fast trainable regressors designed to approximate exact sparse codes, we propose a way of constructing feed-forward neural networks capable of approximating the learned models at a fraction of the computational cost of exact solvers. In the shift-invariant case, this leads to a principled way of constructing task-specific convolutional networks. We illustrate the proposed models on several experiments in music analysis and image processing applications.
Bilevel sparse models for polyphonic music transcription
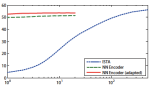
In this work, we propose a trainable sparse model for automatic polyphonic music transcription, which incorporates several successful approaches into a unified optimization framework. Our model combines unsupervised synthesis models similar to latent component analysis and nonnegative factorization with metric learning techniques that allow supervised discriminative learning. We develop efficient stochastic gradient training schemes allowing unsupervised, semi-, and fully supervised training of the model as well its adaptation to test data. We show efficient fixed complexity and latency approximation that can replace iterative minimization algorithms in time-critical applications. Experimental evaluation on synthetic and real data shows promising initial results.
Sparse modeling of intrinsic correspondences
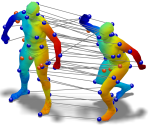
We present a novel sparse modeling approach to non-rigid shape matching using only the ability to detect repeatable regions. As the input to our algorithm, we are given only two sets of regions in two shapes; no descriptors are provided so the correspondence between the regions is not know, nor we know how many regions correspond in the two shapes. We show that even with such scarce information, it is possible to establish very accurate correspondence between the shapes by using methods from the field of sparse modeling, being this, the first non-trivial use of sparse models in shape correspondence. We formulate the problem of permuted sparse coding, in which we solve simultaneously for an unknown permutation ordering the regions on two shapes and for an unknown correspondence in functional representation. We also propose a robust variant capable of handling incomplete matches. Numerically, the problem is solved efficiently by alternating the solution of a linear assignment and a sparse coding problem. The proposed methods are evaluated qualitatively and quantitatively on standard benchmarks containing both synthetic and scanned objects.
Audio restoration from multiple copies
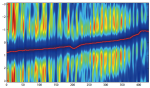
A method for removing impulse noise from audio signals by fusing multiple copies of the same recording is introduced in this paper. The proposed algorithm exploits the fact that while in general multiple copies of a given recording are available, all sharing the same master, most degradations in audio signals are record-dependent. Our method first seeks for the optimal non-rigid alignment of the signals that is robust to the presence of sparse outliers with arbitrary magnitude. Unlike previous approaches, we simultaneously find the optimal alignment of the signals and impulsive degradation. This is obtained via continuous dynamic time warping computed solving an Eikonal equation. We propose to use our approach in the derivative domain, reconstructing the signal by solving an inverse problem that resembles the Poisson image editing technique. The proposed framework is here illustrated and tested in the restoration of old gramophone recordings showing promising results; however, it can be used in other application where different copies of the signal of interest are available and the degradations are copy-dependent.
Learnable low rank sparse models for speech denoising
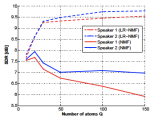
In this paper we present a framework for real time enhancement of speech signals. Our method leverages a new process-centric approach for sparse and parsimonious models, where the representation pursuit is obtained applying a deterministic function or process rather than solving an optimization problem. We first propose a rank-regularized robust version of non-negative matrix factorization (NMF) for modeling time-frequency representations of speech signals in which the spectral frames are decomposed as sparse linear combinations of atoms of a low-rank dictionary. Then, a parametric family of pursuit processes is derived from the iteration of the proximal descent method for solving this model. We present several experiments showing successful results and the potential of the proposed framework. Incorporating discriminative learning makes the proposed method significantly outperform exact NMF algorithms, with fixed latency and at a fraction of it’s computational complexity.
Real-time online singing voice separation from monaural recordings using robust low-rank modeling
Separating the leading vocals from the musical accompaniment is a challenging task that appears naturally in several music processing applications. Robust principal component analysis (RPCA) has been recently employed to this problem producing very successful results. The method decomposes the signal into a low-rank component corresponding to the accompaniment with its repetitive structure, and a sparse component corresponding to the voice with its quasi-harmonic structure. In this paper, we first introduce a non-negative variant of RPCA, termed as robust low-rank non-negative matrix factorization (RNMF). This new framework better suits audio applications. We then propose two efficient feed-forward architectures that approximate the RPCA and RNMF with low latency and a fraction of the complexity of the original optimization method. These approximants allow incorporating elements of unsupervised, semi- and fully-supervised learning into the RPCA and RNMF frameworks. Our basic implementation shows several orders of magnitude speedup compared to the exact solvers with no performance degradation, and allows online and faster-than-real-time processing. Evaluation on the MIR-1K dataset demonstrates state-of-the-art performance.
Learning efficient structured sparse models
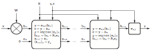
We present a comprehensive framework for structured sparse coding and modeling extending the recent ideas of using learnable fast regressors to approximate exact sparse codes. For this purpose, we propose an efficient feed forward architecture derived from the iteration of the block-coordinate algorithm. This architecture approximates the exact structured sparse codes with a fraction of the complexity of the standard optimization methods. We also show that by using different training objective functions, the proposed learnable sparse encoders are not only restricted to be approximants of the exact sparse code for a pre-given dictionary, but can be rather used as full-featured sparse encoders or even modelers. A simple implementation shows several orders of magnitude speedup compared to the state-of-the-art exact optimization algorithms at minimal performance degradation, making the proposed framework suitable for real time and large-scale applications.
Nonlinear dimensionality reduction by topologically constrained isometric embedding
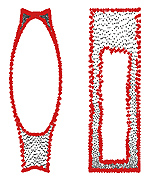
Many manifold learning procedures try to embed a given feature data into a flat space of low dimensionality while preserving as much as possible the metric in the natural feature space. The embedding process usually relies on distances between neighboring features, mainly since distances between features that are far apart from each other often provide an unreliable estimation of the true distance on the feature manifold due to its non-convexity. Distortions resulting from using long geodesics indiscriminately lead to a known limitation of the Isomap algorithm when used to map nonconvex manifolds. Presented is a framework for nonlinear dimensionality reduction that uses both local and global distances in order to learn the intrinsic geometry of flat manifolds with boundaries. The resulting algorithm filters out potentially problematic distances between distant feature points based on the properties of the geodesics connecting those points and their relative distance to the boundary of the feature manifold, thus avoiding an inherent limitation of the Isomap algorithm. Since the proposed algorithm matches non-local structures, it is robust to strong noise. We show experimental results demonstrating the advantages of the proposed approach over conventional dimensionality reduction techniques, both global and local in nature.
Embedded system for 3D shape reconstruction

Many applications that use three-dimensional scanning require a low cost, accurate and fast solution. This paper presents a fixed-point implementation of a real time active stereo threedimensional acquisition system on a Texas Instruments DM6446 EVM board which meets these requirements. A time-multiplexed structured light reconstruction technique is described and a fixed point algorithm for its implementation is proposed. This technique uses a standard camera and a standard projector. The fixed point reconstruction algorithm runs on the DSP core while the ARM controls the DSP and is responsible for communication with the camera and projector. The ARM uses the projector to project coded light and the camera to capture a series of images. The captured data is sent to the DSP. The DSP, in turn, performs the 3D reconstruction and returns the results to the ARM for storing. The inter-core communication is performed using the xDM interface and VISA API. Performance evaluation of a fully working prototype proves the feasibility of a fixed-point embedded implementation of a real time three-dimensional scanner, and the suitability of the DM6446 chip for such a system.
Expression-invariant representation of faces
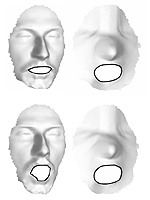
We present an efficient computational framework for isometry-invariant comparison of smooth surfaces. We formulate the Gromov-Hausdorff distance as a multidimensional scaling (MDS)-like continuous optimization problem. In order to construct an efficient optimization scheme, we develop a numerical tool for interpolating geodesic distances on a sampled surface from precomputed geodesic distances between the samples. For isometry-invariant comparison of surfaces in the case of partially missing data, we present the partial embedding distance, which is computed using a similar scheme. The main idea is finding a minimum-distortion mapping from one surface to another while considering only relevant geodesic distances. We discuss numerical implementation issues and present experimental results that demonstrate its accuracy and efficiency.
On separation of semitransparent dynamic images from static background

Presented here is the problem of recovering a dynamic image superimposed on a static background. Such a problem is ill-posed and may arise e.g. in imaging through semireflective media, in separation of an illumination image from a reflectance image, in imaging with diffraction phenomena, etc. In this work we study regularization of this problem in spirit of Total Variation and general sparsifying transformations.
Quasi maximum likelihood blind deconvolution: super- an sub-Gaussianity versus consistency
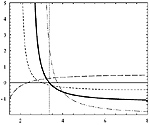
In this note we consider the problem of MIMO quasi maximum likelihood (QML) blind deconvolution. We examine two classes of estimators, which are commonly believed to be suitable for super- and sub-Gaussian sources. We state the consistency conditions and demonstrate a distribution, for which the studied estimators are unsuitable, in the sense that they are asymptotically unstable
Relative optimization for blind deconvolution

We propose a relative optimization framework for quasi-maximum likelihood (QML) blind deconvolution and the relative Newton method as its particular instance. The special Hessian structure allows fast Newton system construction and solution, resulting in a fast-convergent algorithm with iteration complexity comparable to that of gradient methods. We also propose the use of rational IIR restoration kernels, which constitute a richer family of filters than the traditionally used FIR kernels. We discuss different choices of non-linear functions suitable for deconvolution of super- and sub-Gaussian sources and formulate the conditions, under which the QML estimation is stable. Simulation results demonstrate the efficiency of the proposed methods.
Blind deconvolution of images using optimal sparse representations

The relative Newton algorithm, previously proposed for quasi-maximum likelihood blind source separation and blind deconvolution of one-dimensional signals is generalized for blind deconvolution of images. Smooth approximation of the absolute value is used in modeling the log probability density function, which is suitable for sparse sources. In addition, we propose a method of sparsification, which allows blind deconvolution of sources with arbitrary distribution, and show how to find optimal sparsifying transformations by training.
Unmixing tissues: sparse component analysis in multi-contrast MRI
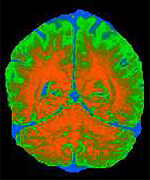
We pose the problem of tissue classification in MRI as a blind source separation (BSS) problem and solve it by means of sparse component analysis (SCA). Assuming that most MR images can be sparsely represented, we consider their optimal sparse representation. Sparse components define a physically-meaningful feature space for classification. We demonstrate our approach on simulated and real multi-contrast MRI data. The proposed framework is general in that it is applicable to other modalities of medical imaging as well, whenever the linear mixing model is applicable.
A multigrid approach for multi-dimensional scaling
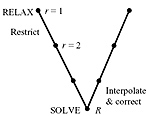
A multigrid approach for the efficient solution of large-scale multidimensional scaling (MDS) problems is presented. The main motivation is a recent application of MDS to isometry-invariant representation of surfaces, in particular, for expression-invariant recognition of human faces. Simulation results show that the proposed approach significantly outperforms conventional MDS algorithms.
Sparse ICA for blind separation of transmitted and reflected images

We address the problem of recovering a scene recorded through a semi-reflecting medium (i.e. planar lens), with a virtual reflected image being superimposed on the image of the scene transmitted through the semi-reflective lens. Recent studies propose imaging through a linear polarizer at several orientations to estimate the reflected and the transmitted components in the scene. In this stud,y we extend the sparse ICA (SPICA) technique and apply it to the problem of separating the image of the scene without having any a priori knowledge about its structure or statistics. Recent novel advances in the SPICA approach are discussed. Simulation and experimental results demonstrate the efficacy of the proposed methods.
Optimal sparse representations for blind source separation and blind deconvolution: a learning approach

We present a generic approach, which allows to adapt sparse blind deconvolution and blind source separation algorithms to arbitrary sources. The key idea is to bring the problem to the case in which the underlying sources are sparse by applying a sparsifying transformation on the mixtures. We present simulation results and show that such transformation can be found by training. Properties of the optimal sparsifying transformation are highlighted by an example with aerial images.
Fast relative Newton algorithm for blind deconvolution of images
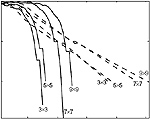
We present an efficient Newton-like algorithm for quasi-maximum likelihood (QML) blind deconvolution of images. This algorithm exploits the sparse structure of the Hessian. An optimal distribution-shaping approach by means of sparsification allows one to use simple and convenient sparsity prior for processing of a wide range of natural images. Simulation results demonstrate the efficiency of the proposed method.
Blind source separation using block-coordinate relative Newton method

Presented here is a generalization of the relative Newton method, recently proposed for quasi maximum likelihood blind source separation. Special structure of the Hessian matrix allows performing block-coordinate Newton descent, which significantly reduces the algorithm computational complexity and boosts its performance. Simulations based on artificial and real data showed that the separation quality using the proposed algorithm is superior compared to other accepted blind source separation methods.
Blind source separation using the block-coordinate relative Newton method
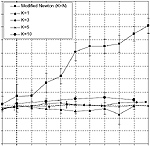
Presented here is a generalization of the modified relative Newton method, recently proposed by Zibulevsky for quasi-maximum likelihood blind source separation. The special structure of the Hessian matrix allows to perform block-coordinate Newton descent, which significantly reduces the algorithm computational complexity and boosts its performance. Simulations based on artificial and real data show that the separation quality using the proposed algorithm outperforms other accepted blind source separation methods.
QML blind deconvolution: asymptotic analysis
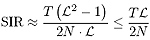
Blind deconvolution is considered as a problem of quasi-maximum likelihood (QML) estimation of the restoration kernel. Simple closed-form expressions for the asymptotic estimation error are derived. The asymptotic performance bounds coincide with the Cramér-Rao bounds, when the true ML estimator is used. Conditions for asymptotic stability of the QML estimator are derived. Special cases when the estimator is super-efficient are discussed.
Optimal sparse representations for blind deconvolution of images
The relative Newton algorithm, previously proposed for quasi-maximum likelihood blind source separation and blind deconvolution of one-dimensional signals is generalized for blind deconvolution of images. Smooth approximation of the absolute value is used in modeling the log probability density function, which is suitable for sparse sources. We propose a method of sparsification, which allows blind deconvolution of sources with arbitrary distribution, and show how to find optimal sparsifying transformations by training.
Quasi maximum likelihood blind deconvolution of images acquired through scattering media

We address the problem of restoration of images obtained through a scattering medium. We present an efficient quasi-maximum likelihood blind deconvolution approach based on the fast relative Newton algorithm and optimal distribution shaping approach (sparsification), which allows to use simple and convenient sparsity prior for a wide class of images. Simulation results prove the efficiency of the proposed method.
Separation of semireflective layers using Sparse ICA
We address the problem of Blind Source Separation (BSS) of superimposed images and, in particular, consider the recovery of a scene recorded through a semi-refective medium (e.g. glass windshield) from its mixture with a virtual reflected image. We extend the Sparse ICA (SPICA) approach to BSS and apply it to the separation of the desired image from the superimposed images, without having any a priori knowledge about its structure and/or statistics. Advances in the SPICA approach are discussed. Simulations and experimental results illustrate the efficiency of the proposed approach, and of its specific implementation in a simple algorithm of a low computational cost. The approach and the algorithm are generic in that they can be adapted and applied to a wide range of BSS problems involving one-dimensional signals or images.